

Multi-mode-based conference spokesman identity non-inductive confirmation method
A speaker, multi-modal technology, applied in neural learning methods, character and pattern recognition, biological neural network models, etc., to achieve high accuracy and improve efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
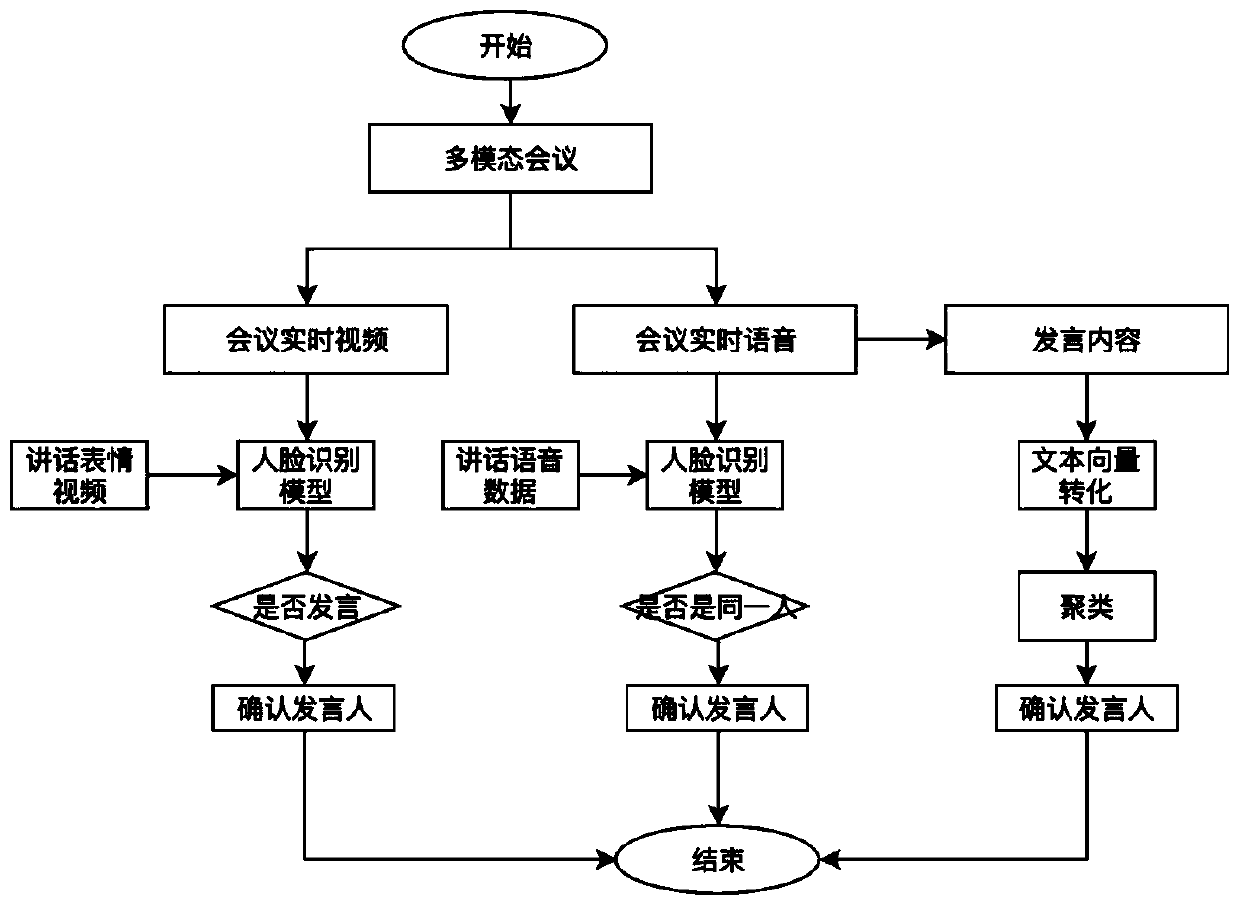
[0035] Collected about 1,000 face photos of speakers at the meeting site, manually classified these photos into speech and non-speech categories, and then used basic operations such as random interference, deformation, and rotation, and then used the Gan network to generate more The training set of the source data set is about 10 times larger than the original data set. Then use the Faster R-Cnn model to train the sample data, and the final model accuracy rate reaches 85%.
[0036] For speaker voice recognition, as a specific embodiment of the present invention, it is: 1) data collection: real-time collection of voice data at the meeting site, and the data is segmented every 4-8 seconds, preferably 5 seconds, and each section is used as a processing unit; 2 ) data processing: because the speeches at the meeting site are relatively standardized, mostly in Mandarin, and the venue is relatively quiet with less noise, so basically there is no need for data processing; 3) model con...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More