

Resume information extraction method and system
An information extraction and resume technology, applied in the field of information extraction, can solve the problems of no classification and exact answers, lower accuracy of supervised classification methods, word segmentation affecting information extraction results, etc., to save training time and reduce manual work. Quantity, good effect of semi-supervised training effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0032] The present invention will be described in further detail below in conjunction with accompanying drawings and examples.
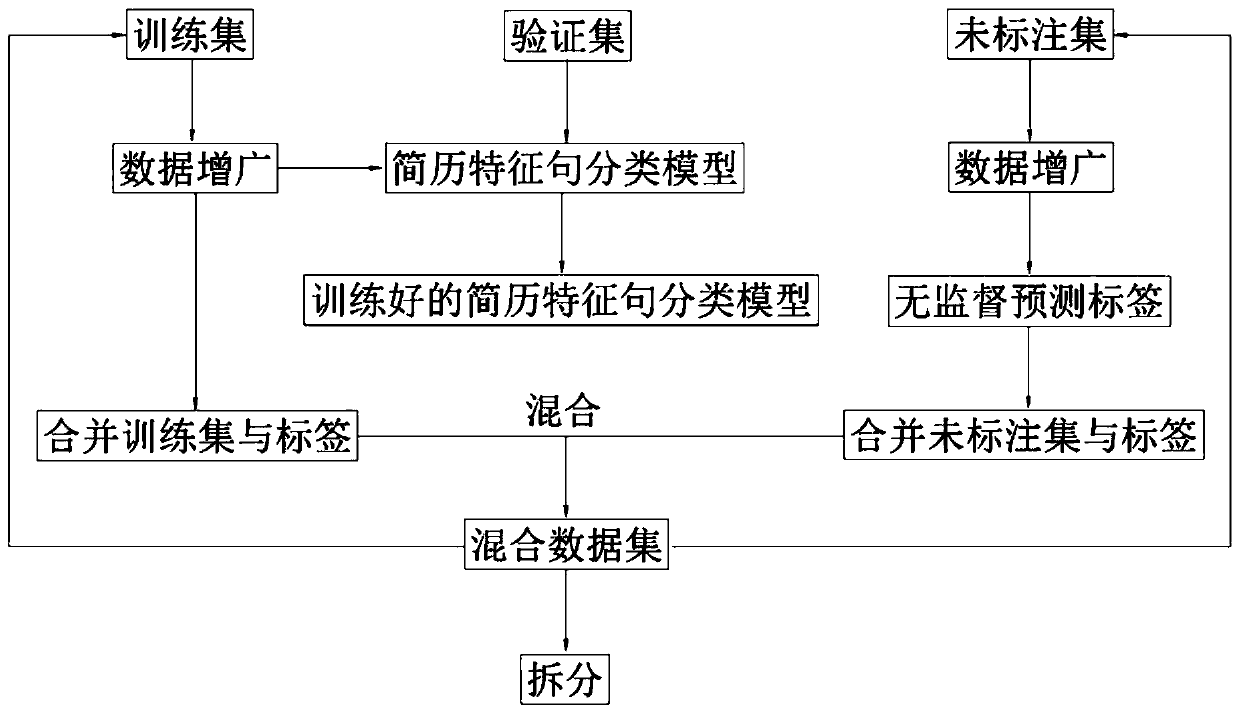
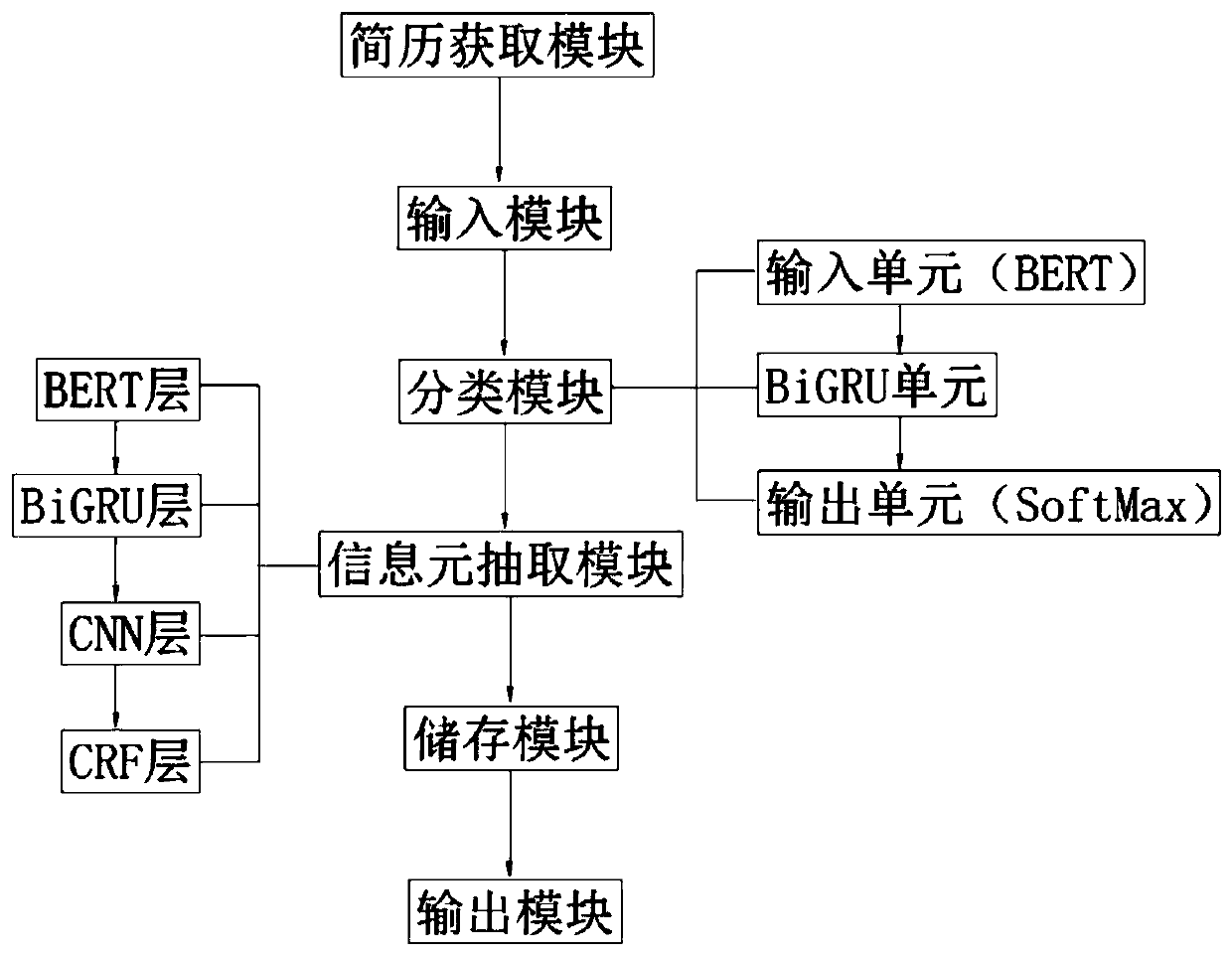
[0033] see Figure 1-2 As shown, the present invention relates to a resume information extraction method, comprising the following steps:
[0034] A. Obtain resume data;
[0035] B. Use BERT Chinese pre-training model and data augmentation technology to convert resume data into resume text and classify according to its sentence features;
[0036] C. Use the BERT+BiGRU+CNN+CRF model to perform named entity recognition on the classified resume text sentences, and then extract the required information elements;
[0037] D. Store the extracted information elements in the database, and output the corresponding information in a structured manner.
[0038] In order to reduce the impact of word segmentation on the processing results of the above technical solution, in step B, the sentences in the resume text are directly converted into vectors as the inpu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More