

SKA task scheduling system and method based on genetic algorithm and computing topology model
A task scheduling and topology model technology, applied in the field of big data, can solve problems such as characteristics that are not considered, and achieve the effects of high throughput, short task completion time, and high throughput
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

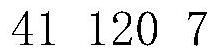
Examples
Embodiment 1
[0053] According to a kind of SKA task scheduling system based on genetic algorithm and computing topology model provided by the present invention, comprising:
[0054] Module M1: The server forms a vector X according to the processing time required by each subtask of the parallel task, obtains the data processing capability of each node according to the number of CPU cores, and forms the data processing capability of each node into a vector Y, according to the vector X and the vector Y And parallel task allocation scheme A, constructing a computing topology model;
[0055] Module M2: The server uses the genetic algorithm to obtain the suboptimal scheduling scheme based on the dependencies between the subtasks of the parallel tasks and the completion time required for each task;
[0056] Module M3: The server obtains the suboptimal scheduling scheme by calculating the topology model to obtain the task scheduling scheme, obtains the completion time required for each task accord...
Embodiment 2
[0082] Embodiment 2 is a modification of embodiment 1
[0083] The following is a detailed introduction in combination with specific examples. This example is carried out on the premise of the technical solution of the present invention, and a detailed implementation mode and specific operation process are given.
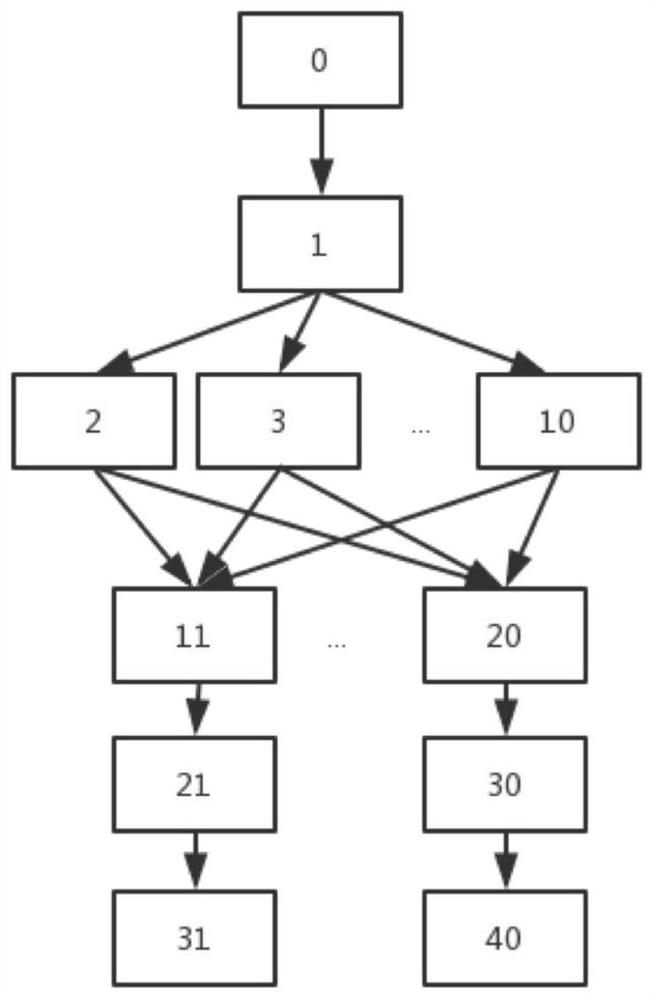
[0084] First, we use a parallel task job as our example. The computing topology of the job is as follows figure 1 shown.
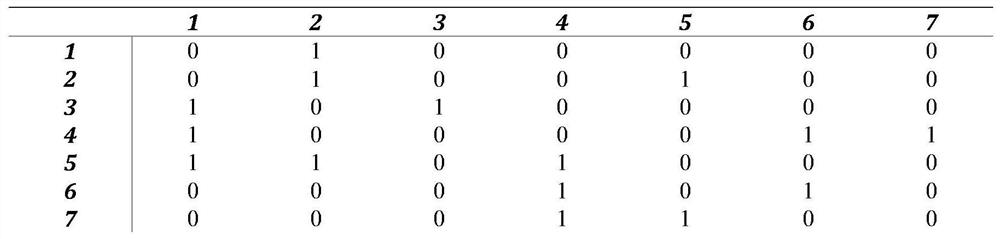
[0085] We convert the dependencies between tasks of the job into an input file whose format is as follows:
[0086]
[0087]
[0088] There are three numbers in the first row, respectively representing the total number of tasks (41), the number of dependencies between tasks (120), that is, the number of edges in the graph and the number of computing nodes (7). The second row is the running time of each task. The running time of task No. 0 is at the first, the running time of task No. 1 is at the second, and so on, separated by spaces. ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More