Single-channel human voice and background voice separation method based on convolutional recurrent neural network
A technology of cyclic neural network and convolutional neural network, which is applied in speech analysis, instruments, etc., can solve problems such as poor separation of human voice and background sound, and inability to accurately extract voice time domain and frequency domain information.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
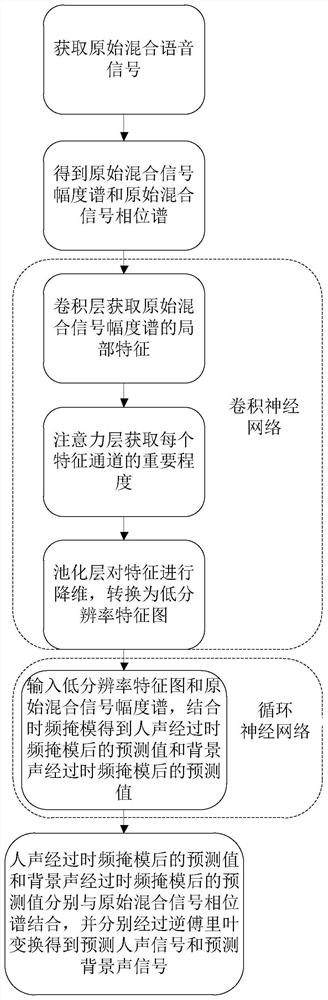
[0036] A single-channel human voice and background sound separation method based on convolutional cyclic neural network, including steps:
[0037] S1. Acquiring an original mixed voice signal, the original voice signal being a single-channel mixed signal of human voice and background sound;
[0038] S2, the obtained original mixed speech signal is subjected to frame division, windowing and time-frequency conversion to obtain the original mixed signal amplitude spectrum and the original mixed signal phase spectrum;
[0039] S3, the original mixed signal amplitude spectrum is input into the convolutional neural network, and the convolutional neural network includes a convolutional layer and a pooling layer arranged in sequence; the convolutional layer obtains the local features of the original mixed signal amplitude spectrum, and the pooling layer pairs The feature is dimensionally reduced, converted into a low-resolution feature map and output; the convolutional layer includes ...
Embodiment 2
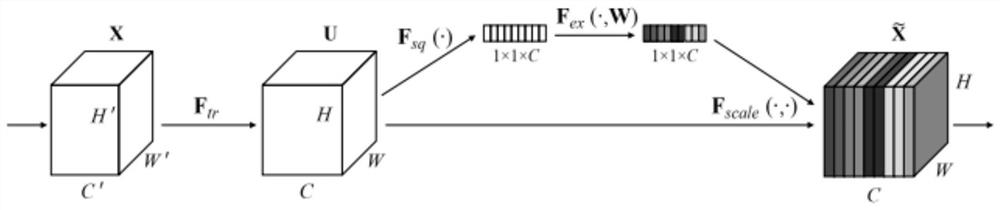
[0053] like figure 1 and 2 As shown, on the basis of Embodiment 1, this embodiment also includes: there is an attention layer between the convolution layer and the pooling layer of the convolutional neural network, and the attention layer automatically acquires each feature by learning According to the importance of the channel, the weight of useful feature channels is increased according to the importance, and the feature channels that are not very useful for the current task are suppressed. figure 2 Represents the attention layer. The attention layer is arranged between the convolutional layer and the pooling layer.
[0054] Preferably, the attention layer adopts a maximum pooling method for global pooling.
[0055] figure 2A schematic diagram of the attention layer of this embodiment is provided. Given an input x, the number of feature channels is c_1, and after a series of general transformations such as convolution, a feature with a number of feature channels of c_2...
PUM
 Login to view more
Login to view more Abstract
Description
Claims
Application Information
 Login to view more
Login to view more - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap