Data storage method of FPGA-based real symmetric matrix eigenvalue decomposition
A technology of eigenvalue decomposition and symmetric matrix, which is applied in the field of signal processing, can solve problems such as no reference, pipeline performance impact, etc., and achieve the effect of saving storage resources
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0027]The present invention will be described in detail below with reference to the drawings and preferred embodiments, and the objectives and effects of the present invention will become appreciated, and it is understood that the specific embodiments described herein are intended to illustrate only the invention and are not intended to limit the invention.
[0028]Firstly, the technical term explanation is given:
[0029](1) FPGA: Field Programmable Gate Array Scene Programmable Gate Array
[0030](2) RAM: Random Access Memory Random Memory, Here, FPGA internal RAM
[0031](3) Jacobi: Here specifies the cross-line bilateral Jacqueri rotation, often used by FPGA-based matrix eigenvalue decomposition
[0032](4) BRAM: Block Ram, FPGA internal block RAM
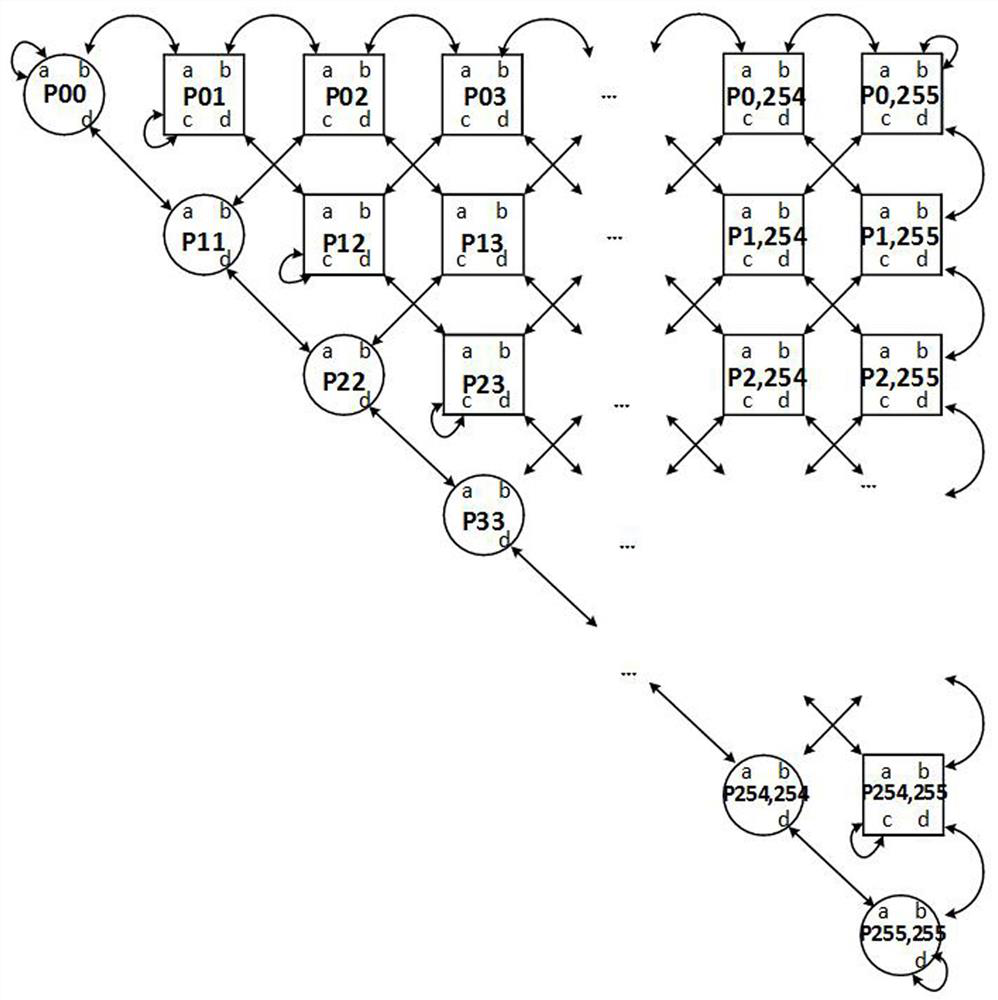
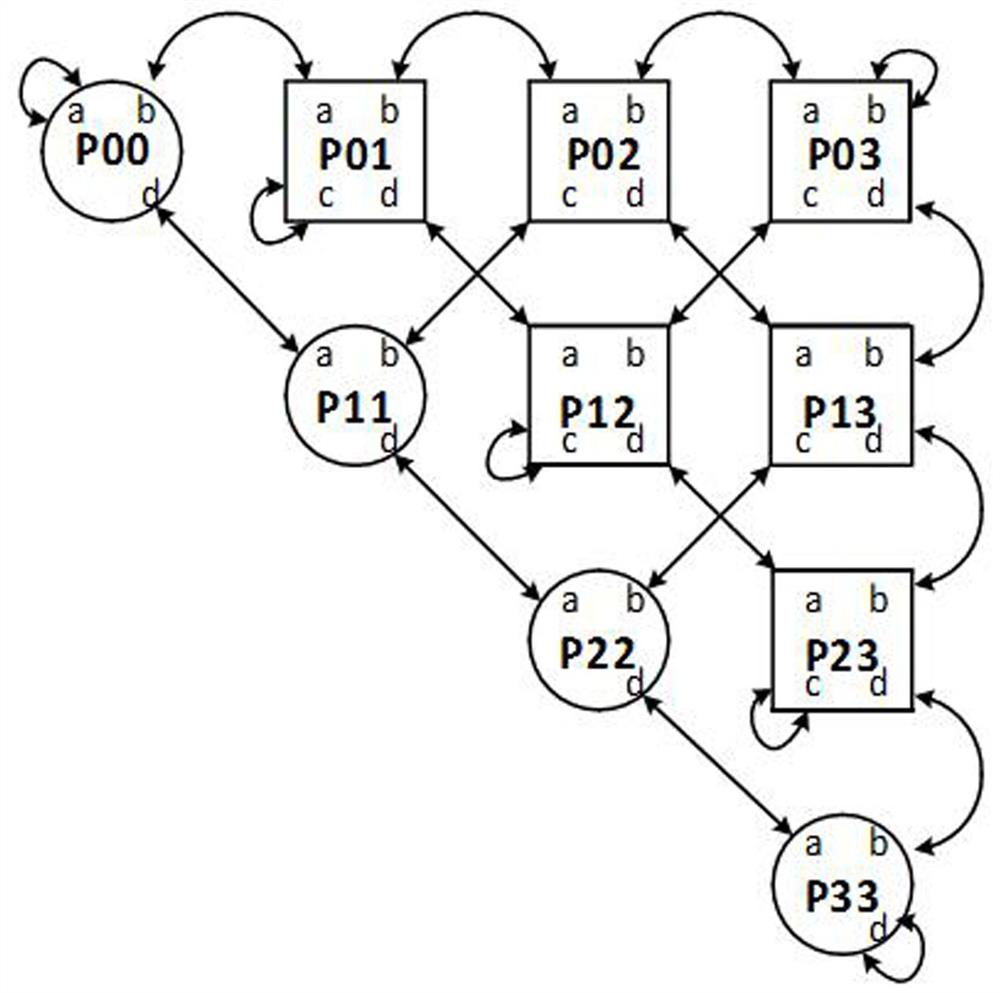
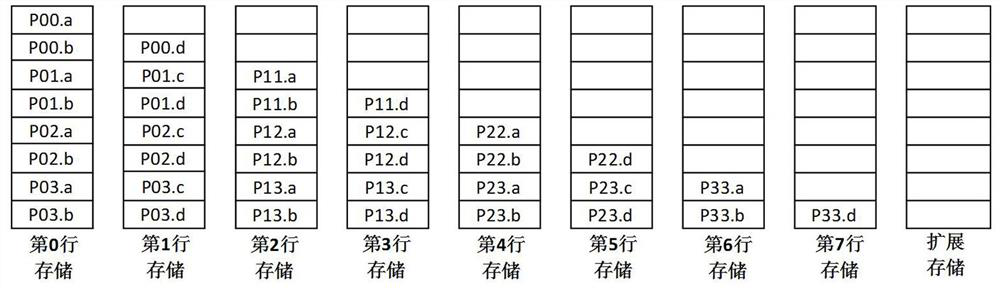
[0033]According to an FPGA-based data storage method, the active symmetrical matrix is 2n row × 2n column, and the number of elements of the upper triangular array structure after the active symmetric matrix is transmitted. Near half of the storag...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More