

A text classification method
A text classification and text data technology, applied in text database clustering/classification, neural learning methods, unstructured text data retrieval, etc., can solve problems such as the inability to provide better text information long-distance dependence, and achieve improved Effects of anti-interference, guaranteed effectiveness, and smooth weight update
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
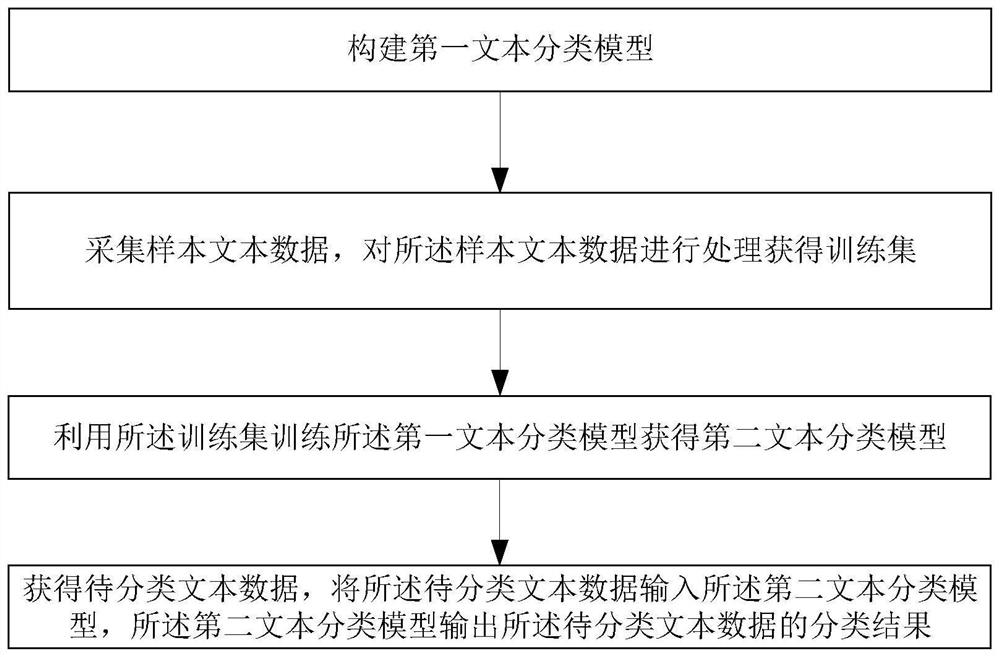
[0041] Please refer to figure 1 , figure 1 A schematic flowchart of a text classification method, Embodiment 1 of the present invention provides a text classification method, and the method includes:
[0042] Build the first text classification model;
[0043] collecting sample text data, and processing the sample text data to obtain a training set;
[0044] Using the training set to train the first text classification model to obtain a second text classification model;
[0045] The text data to be classified is obtained, and the text data to be classified is input into the second text classification model, and the second text classification model outputs a classification result of the text data to be classified.
[0046] This method is described in detail below:
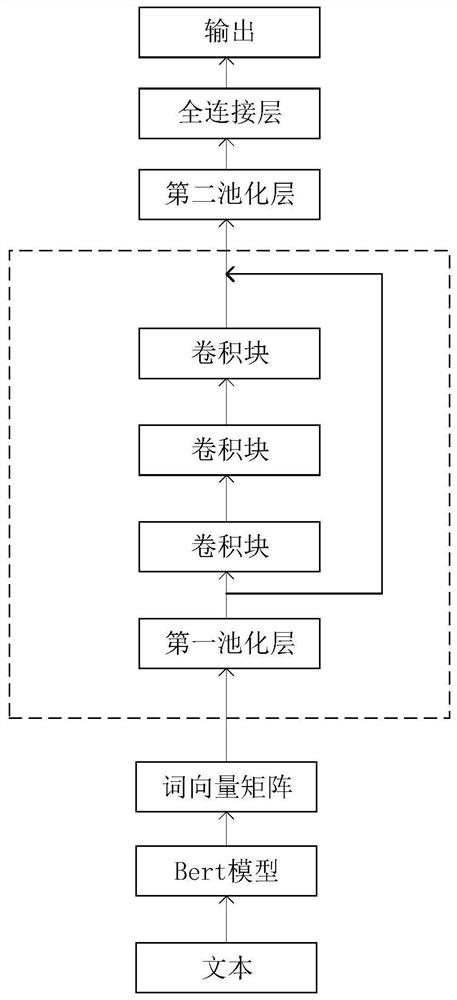
[0047] In view of the shortcomings and deficiencies of the existing text classification problem, this embodiment provides a text classification method based on Bert-DPCNN model improvement, word segmentation data ...
Embodiment 2
[0077] The technical scheme adopted by the present invention is: a text classification method based on Bert-DPCNN model improvement, word segmentation data enhancement, and confrontation learning, including the following steps:
[0078]Data preprocessing. Divide the used data set into training set, test set, and verification set according to the ratio of 8:1:1, and process the special characters, spaces, expressions, etc. that may appear in the data set. Based on the pre-training model, the above-mentioned The divided first text set is encoded with character vectors and a list of data structures and labels that can be recognized by the word segmentation model. Chinese word segmentation is carried out in units of words. For each token character, the word list index of the character is returned, and the flags [CLS] and [SEP] are added at the beginning and end of the text tagging sequence. The length of the sentences in the data set is uniform, and the sequence length is too small...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More