

Quadruped robot motion control method based on reinforcement learning and position increment
A quadruped robot and robot movement technology, applied in the direction of adaptive control, general control system, control/regulation system, etc., can solve the problems of unobtainable performance motion control strategy, motor damage, increasing reward function design and parameter adjustment difficulty, etc. problems, to avoid permanent physical damage to the motor, to avoid mutations, to reduce the difficulty of manual design and the effect of human labor burden
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
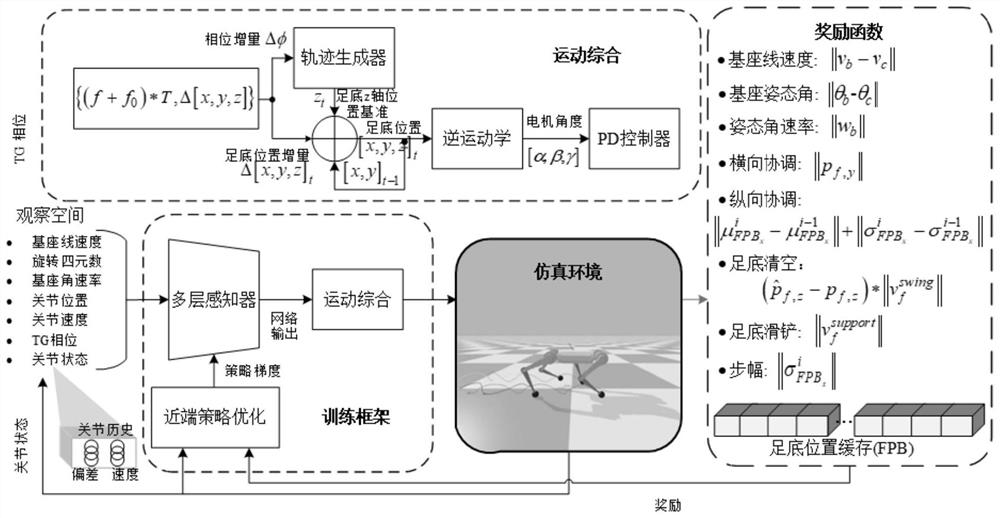
[0039] In an exemplary embodiment of the present invention, as Figure 1-Figure 4 As shown, a motion control method for quadruped robot based on reinforcement learning and position increment is presented.
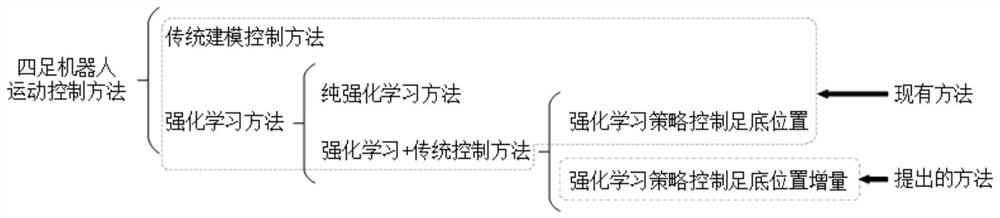
[0040] like figure 1 As shown, different from the existing gait control methods of quadruped robots, this embodiment proposes a quadruped robot motion control method based on reinforcement learning and position increment, which allows the quadruped robot to learn the sole of each time step. The amount of change in position, avoiding abrupt changes in control commands, enables the quadruped robot to learn smooth and coordinated movements within the RL framework and reduces the difficulty of hyperparameter tuning during the training phase. Reinforcement learning needs to interact with the environment to learn, and the trial-and-error and randomness of the strategy in the early stage of training is likely to cause irreversible damage and damage to the robot, making it impossi...
Embodiment 2
[0088] In another exemplary embodiment of the present invention, as Figure 1-Figure 4 As shown, a motion control system for quadruped robot based on reinforcement learning and position increment is presented.
[0089] include:
[0090] an information acquisition module, configured to: acquire motion environment information, quadruped robot posture information and sole position information;
[0091] Incremental calculation module: configured to: based on the obtained information, generate the position of the sole of the foot in each preset time step when the quadruped robot moves, and calculate the variation of the position of the sole of the foot in each time step;
[0092] The trajectory planning module is configured to: take the maximum moving distance in a single time step as a constraint, and accumulate the time step to obtain the plantar position trajectory;
[0093] The action control module is configured to: control the quadruped robot to perform corresponding action...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More