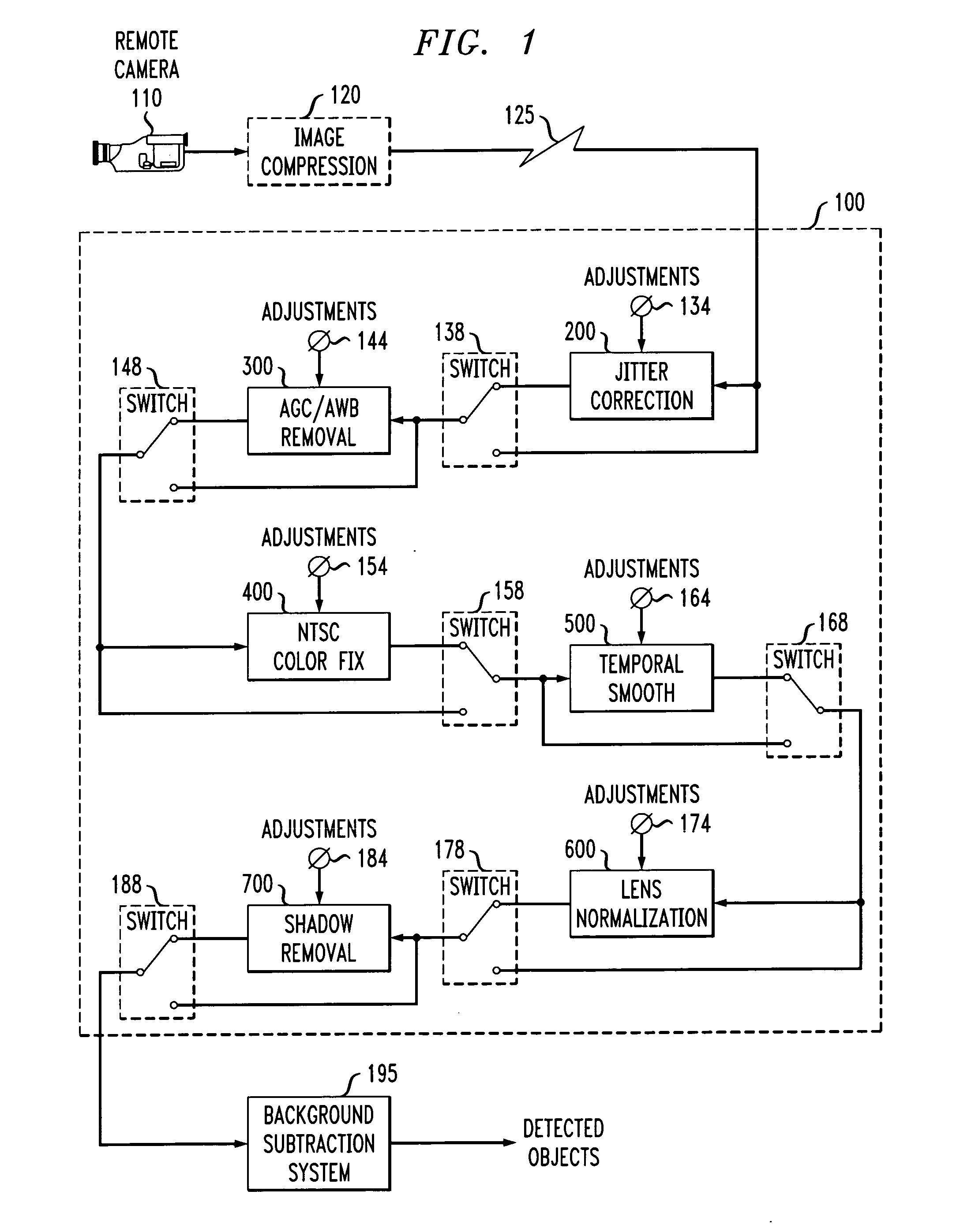
Unfortunately, there are numerous factors that can adversely
impact the
efficacy of this class of techniques.
Such disturbances include changes in camera responses due to automatic
gain and color-balance corrections, image
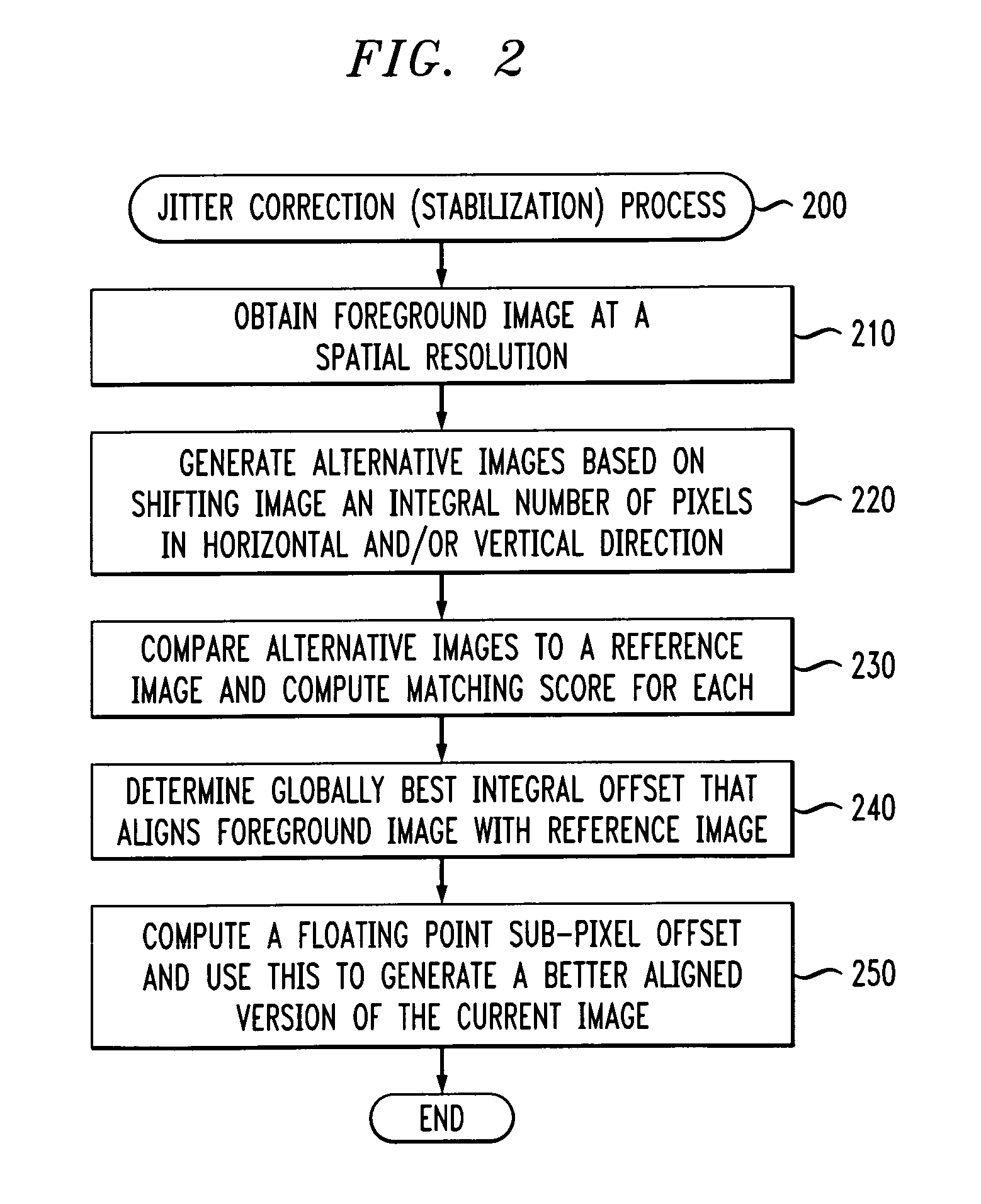
jitter due to vibration or wind, perceptually-masked artifacts due to video compression or cabling inadequacies, and varying object size due to lens
distortion or imaging angle.
Some of these problems have simple solutions, but they are not optimal.
While video can be transmitted and recorded in an uncompressed state, the required bandwidth and disk-storage space increases costs significantly.
Although it is possible to correct imaging geometry, this is difficult to cope with in practice because it involves moving cameras to optimal viewing locations.
Such locations may be inconvenient (e.g., requiring significantly longer cable runs) or not feasible (e.g., above the ceiling level).
The solutions to other problems are not as straightforward.
However these solutions require changing the cameras that are already installed.
Also, these solutions are typically bulkier than an ordinary fixed camera and hence may be difficult to install in some locations.
However, these pixel shifts are typically integer pixel shifts that are not accurate enough to remove all the artifacts generated by background subtraction.
However, this analysis is mathematically complicated thus necessitating either a lower video
frame rate or a more expensive computation engine.
Unfortunately, these corrections can impair
machine analysis of the images because there are frame to frame variations that are not due to any true variation in the imaged environment.
Some cameras allow AGC and AWB to be disabled, however, this may not be true for all (possibly legacy) cameras in a video surveillance
system.
Also, it is sometimes desired to analyze previously recorded material where the source camera and its parameters can not be controlled retroactively.
While it is possible to correct
exposure and
color balance using techniques such as
histogram stretching or contrast stretching, these whole-image methods can be confused if the content of the scene changes.
Unfortunately, when separating these two signals to reconstruct the
image representation, sharp changes in the intensity
signal can be interpreted as color shifts.
This
aliasing results in strobing color
rainbow patterns around sharp edges.
This can be disadvantageous for
computer vision systems that need to know the true colors of regions, or for
object detection and tracking systems based on background subtraction which may erroneously interpret these color fluctuations as moving objects.
However, this
processing removes potentially valuable information from the image.
However, this approach is sub-optimal in that the boundaries of objects (and sometimes even their identities) can be obscured by such blurring.
Unfortunately, many times video has been subject to a
lossy compression method, such as MPEG (especially if it has been digitally recorded), in which case the exact details of the original waveform cannot be recovered with sufficient fidelity to permit this re-
processing.
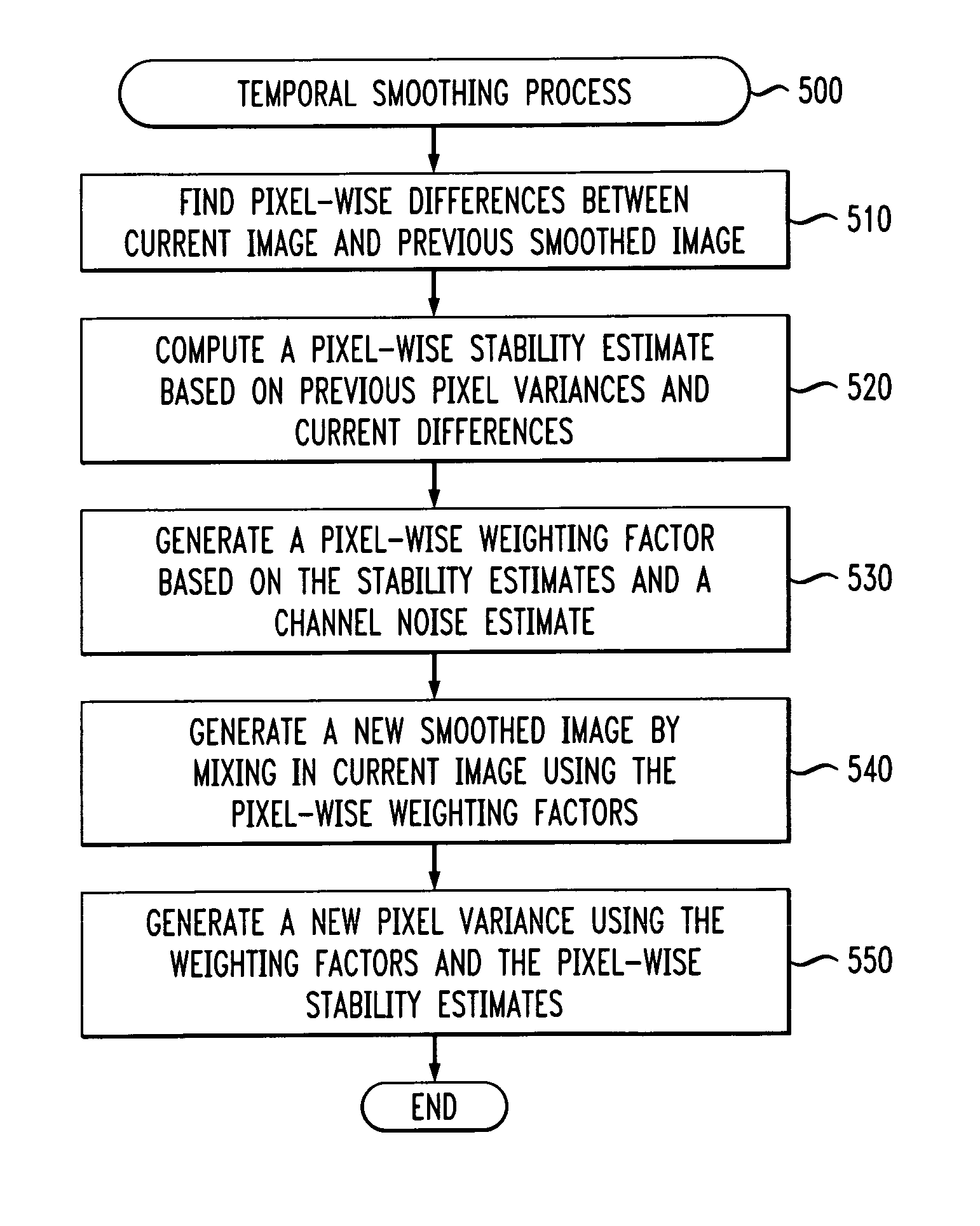
A further problem is that video images often contain “
noise” that is annoying to humans and can be even more detrimental to automated analysis systems.
Unfortunately, this tends to wash out sharp edges and obscure region textures.
Median-based filtering attempts to preserve sharp edges, but still corrupts texture (which is interpreted as
noise) and leads to artificially “flat” looking images.
This works well for largely stationary images, but moving objects often appear ghostly and leave trails behind.
Yet another difficulty is that background subtraction operates by comparing the current image with a
reference image and highlights any pixel changes.
Unfortunately, while often the desired result is the delineation of a number of physical objects, shadow regions are typically also marked because the scene looks different here as well.
Unfortunately, this method requires the computation of
hue, which is typically expensive because it involves trigonometric operators.
Moreover,
hue is unstable in regions of low saturation or intensity (e.g., shadows).
Finally, the derived
hue is very sensitive to the
noise in each color channel (the more noise, the less reliable the estimate).



 Login to View More
Login to View More  Login to View More
Login to View More