

Time Series Similarity Query Method Based on Inverted Index
A time series and inverted index technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve the problems of query performance differences, low index overhead, low data scale scalability, etc., and achieve low space overhead and maintenance costs, reducing disk I/O overhead, and stabilizing scalability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0036] The present invention will be described in further detail below in conjunction with the accompanying drawings.
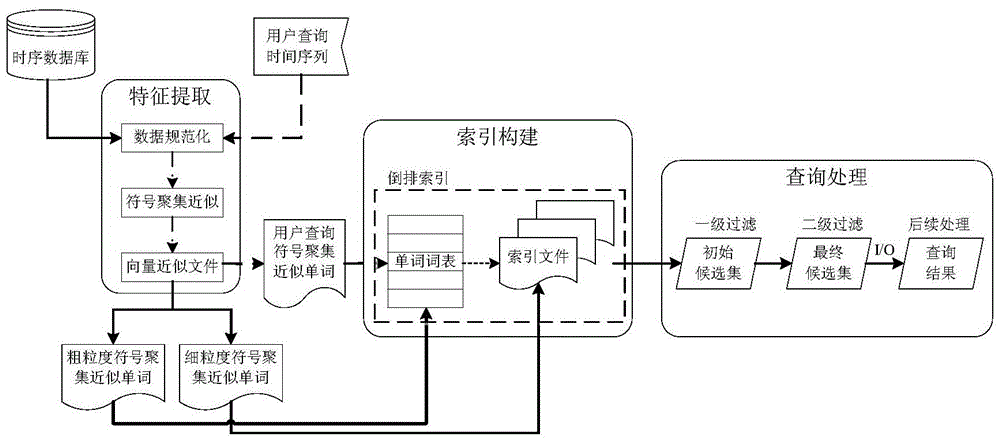
[0037] Such as figure 1 As shown, the time series similarity query method based on the inverted index of the present invention comprises the following steps:
[0038] (1) Index construction, specifically including the following sub-steps:
[0039] (1.1) Read each time series T={t of the time series database sequentially 1 ,t 2 ,...,t i ,...,t n};
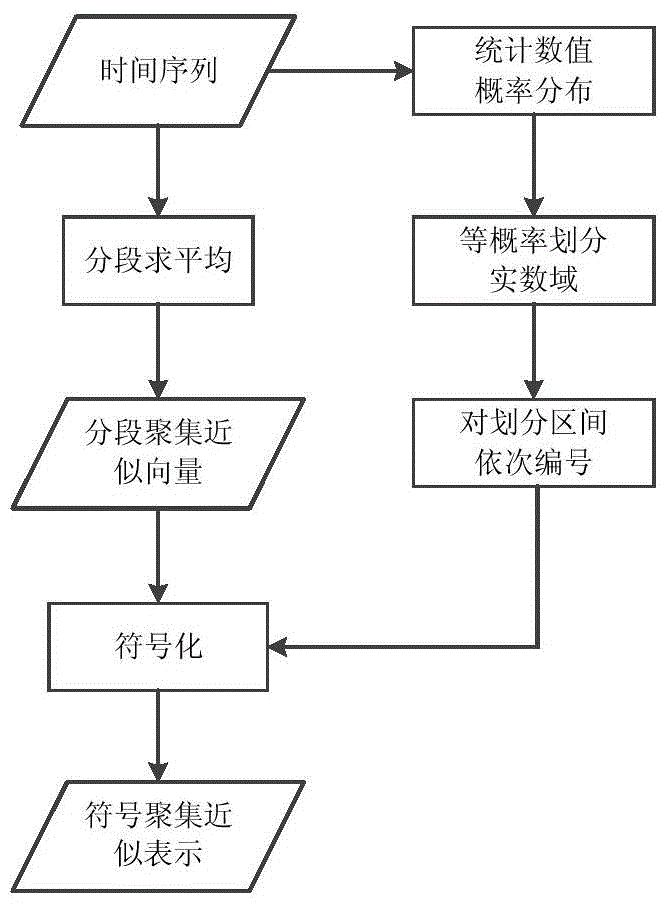
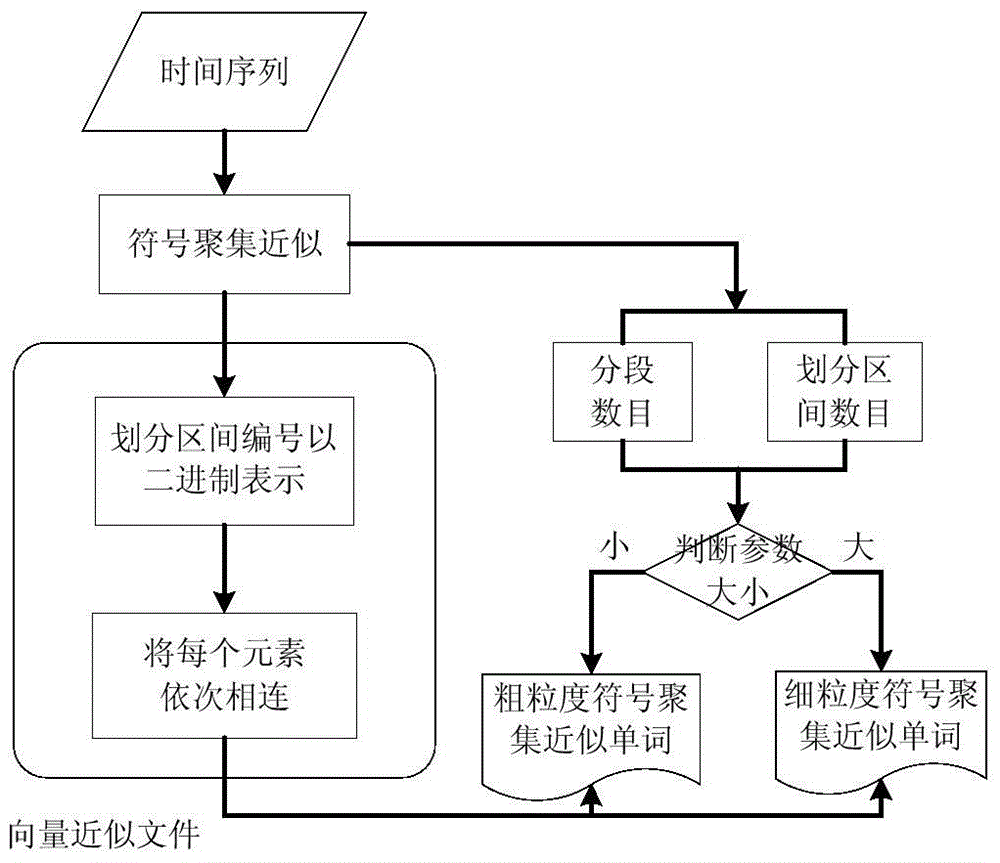
[0040] (1.2) Perform feature extraction on the time series T to obtain the coarse-grained symbol aggregation approximate word SW' and the fine-grained symbol aggregation approximate word SW"; specifically:
[0041] (1.2.1) For the time series T, calculate the mean m and standard deviation σ of all the sampling points, and perform Z-normalization processing on T according to the formula (1), and obtain the normalized time series T'={t' 1 ,t' 2 ,...,t' i ,...,t' n};
[0042]
[0043] (1.2.2) Use symbol ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More