

Spark platform based high efficiency text classification method
A text classification and high-efficiency technology, applied in the field of big data processing, can solve the problems of not being able to use PCs, low resource utilization, and increased network transmission, and achieve the goal of improving cluster resource utilization, promoting improvement, and improving accuracy Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

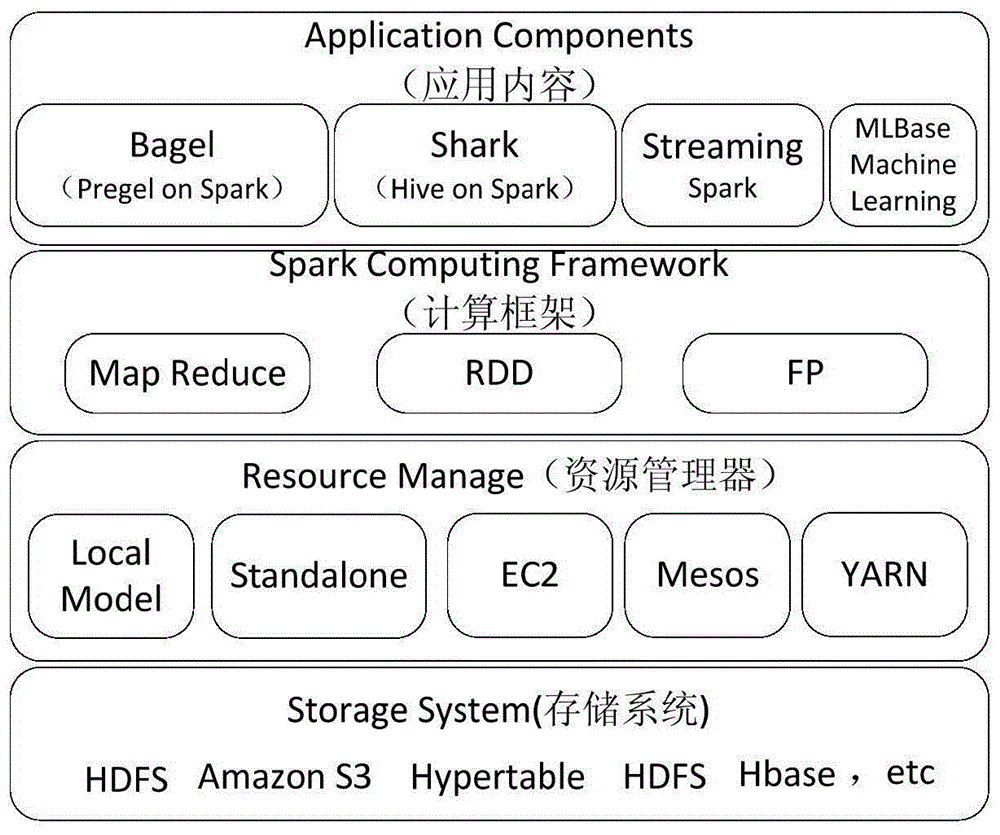
Examples
Embodiment Construction
[0049] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
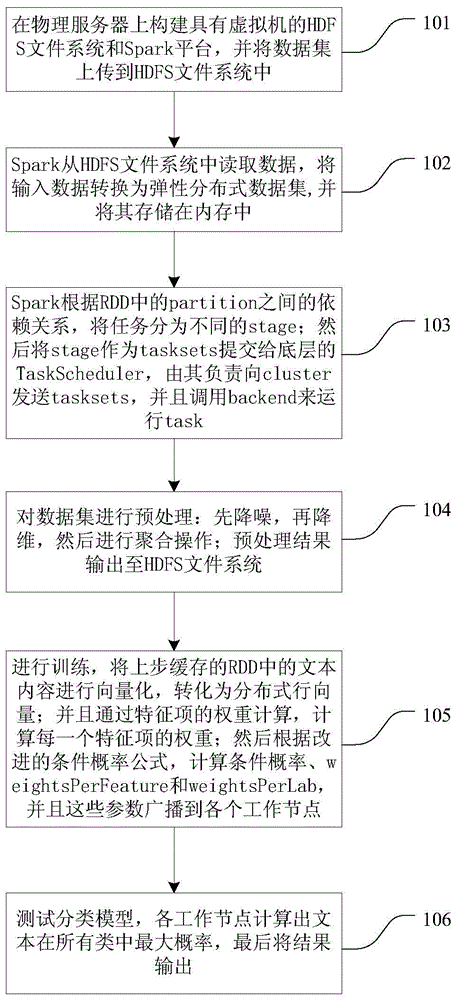
[0050] see figure 1 , the high-efficiency text classification method based on Spark platform in the present embodiment comprises the following steps:
[0051] Step 101: Construct the HDFS file system and the Spark platform with the virtual machine on the physical server, and upload the data set to the HDFS file system.
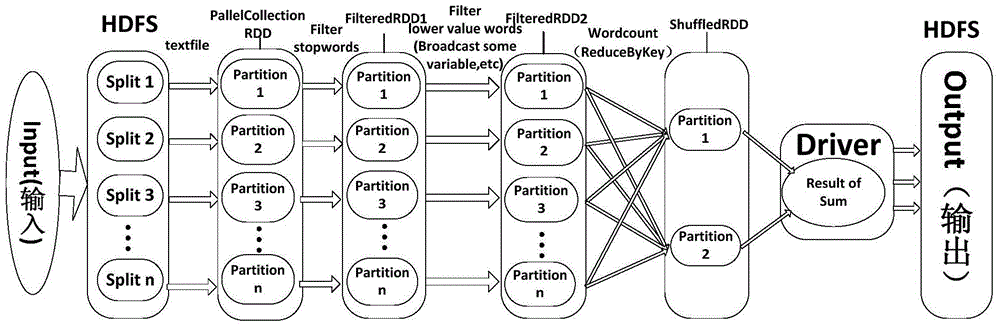
[0052] Step 102: Submit jobs to the Spark cluster through the client, Spark reads data from the HDFS file system, converts the input data into a resilient distributed dataset (RDD) and starts a certain number of partitions according to the number of partitions in the RDD set by th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More