

Spark semantics based data reuse method and system thereof
A data and semantic technology, applied in the field of data reuse method and system based on Spark semantics, can solve the problems of no reuse cache data migration function, inability to perform automatic cache operation, low data reuse rate, etc., to reduce repeated data calculation. , Increase the memory capacity of the cluster, and accelerate the effect of computing
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
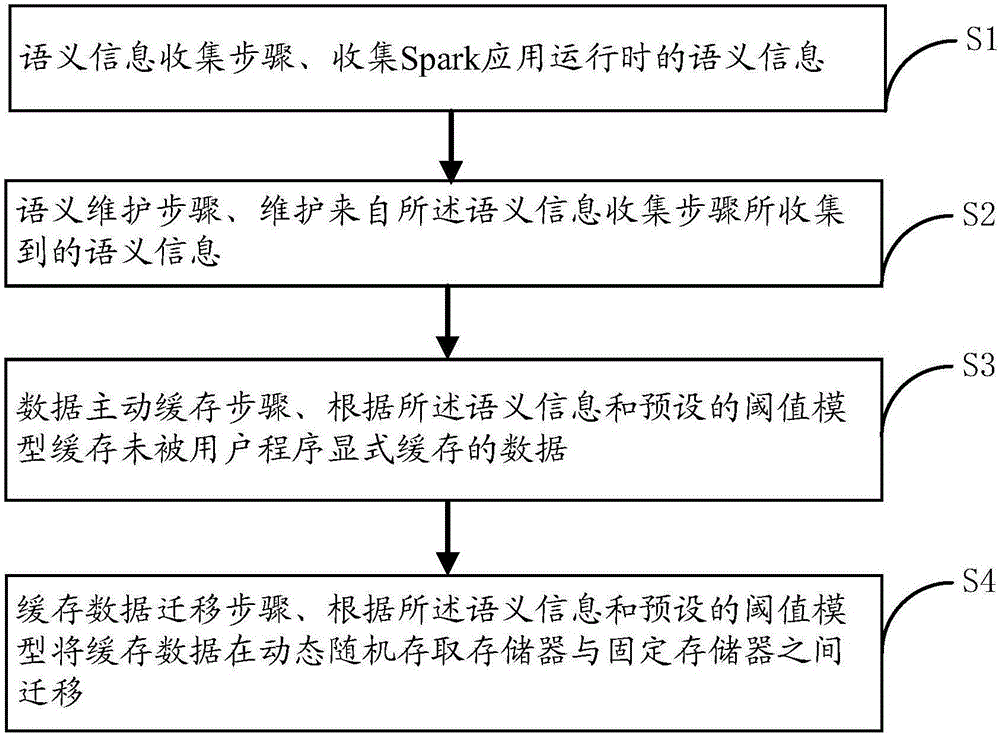
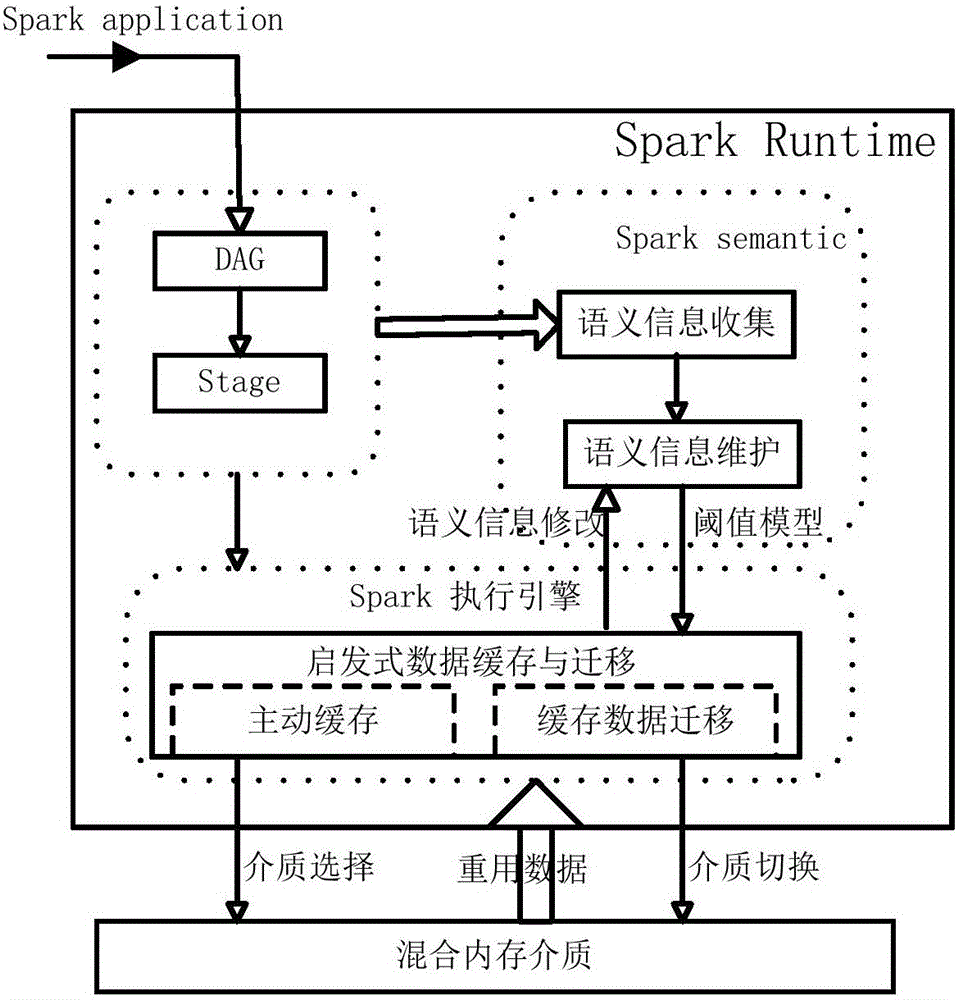
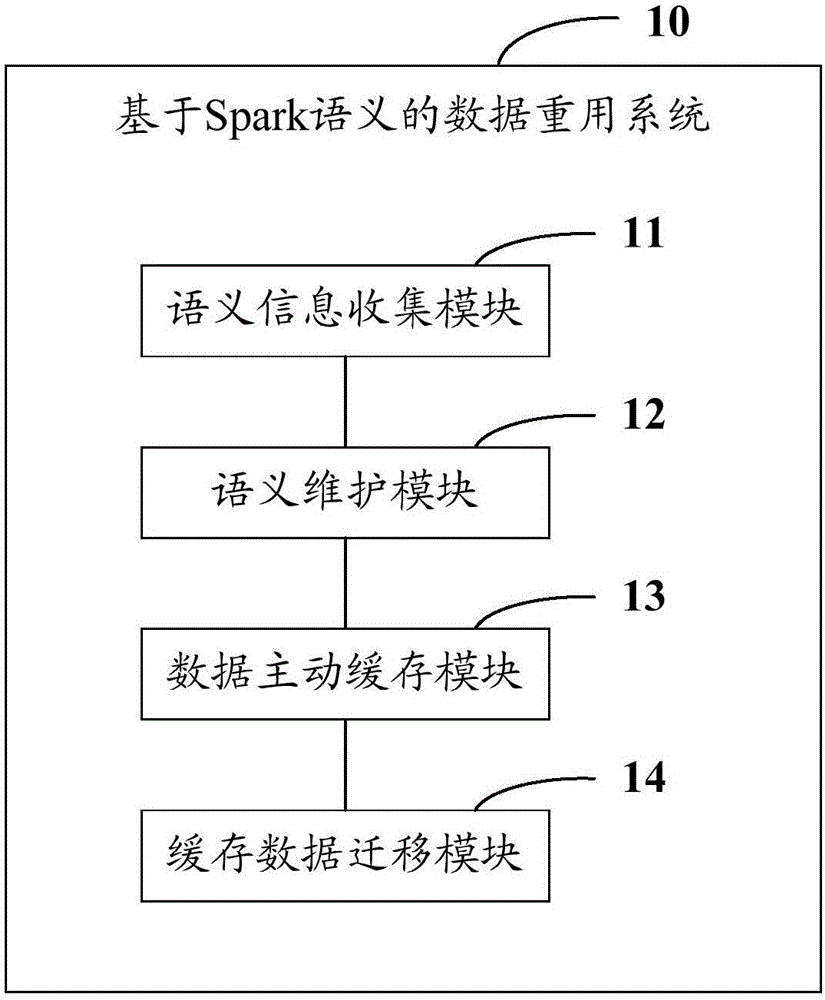
[0020] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
[0021] In the technical solution provided by the present invention, in order to improve the efficiency of data reuse in Spark and accelerate calculation, it is necessary to design a heuristic data caching and migration mechanism in Spark that can adapt to mixed memory media. The reason is that in the application of this iterative computing framework, the more repeated operations are required, the larger the amount of data to be read, and the greater the benefit of computing. Machine learning algorithms and interactive queries are typical applications that require Cache operation on reused data; non...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More