

A Method of Writing Checkpoint Data in Massively Parallel Systems Based on Random Latency Alleviating I/O Bottleneck
A random delay and system check technology, applied in the field of high-performance computing, can solve problems such as unrecoverable operation of node-related processes, loss of checkpoint data, I/O system impact, etc., to improve scalability, reduce performance loss, and slow down The effect of writing peaks
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

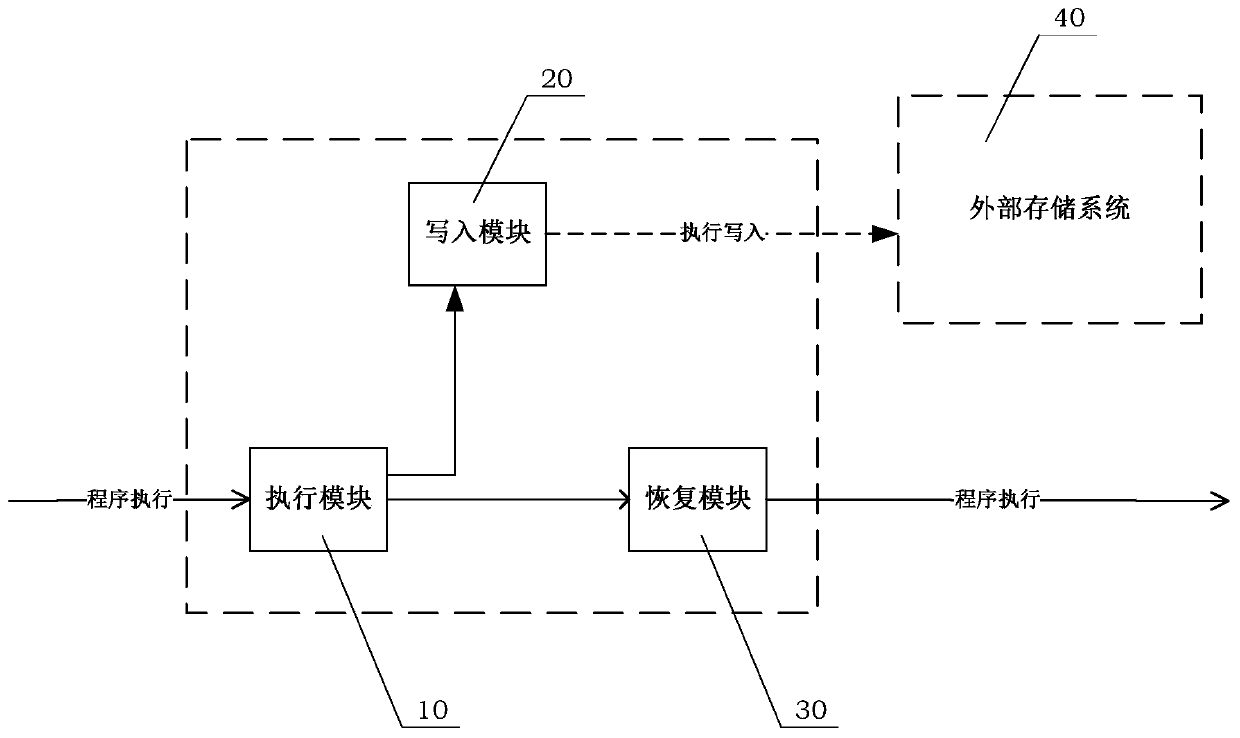
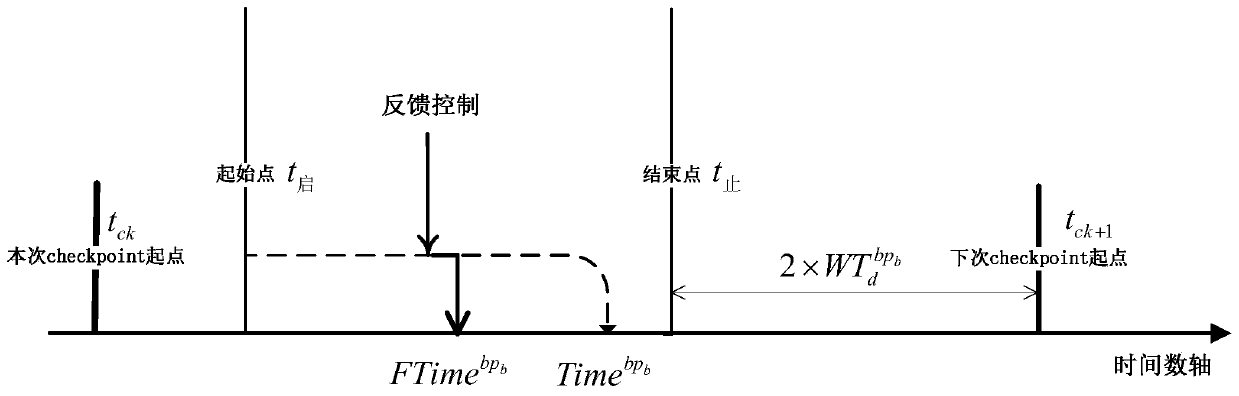
Examples
Embodiment 1
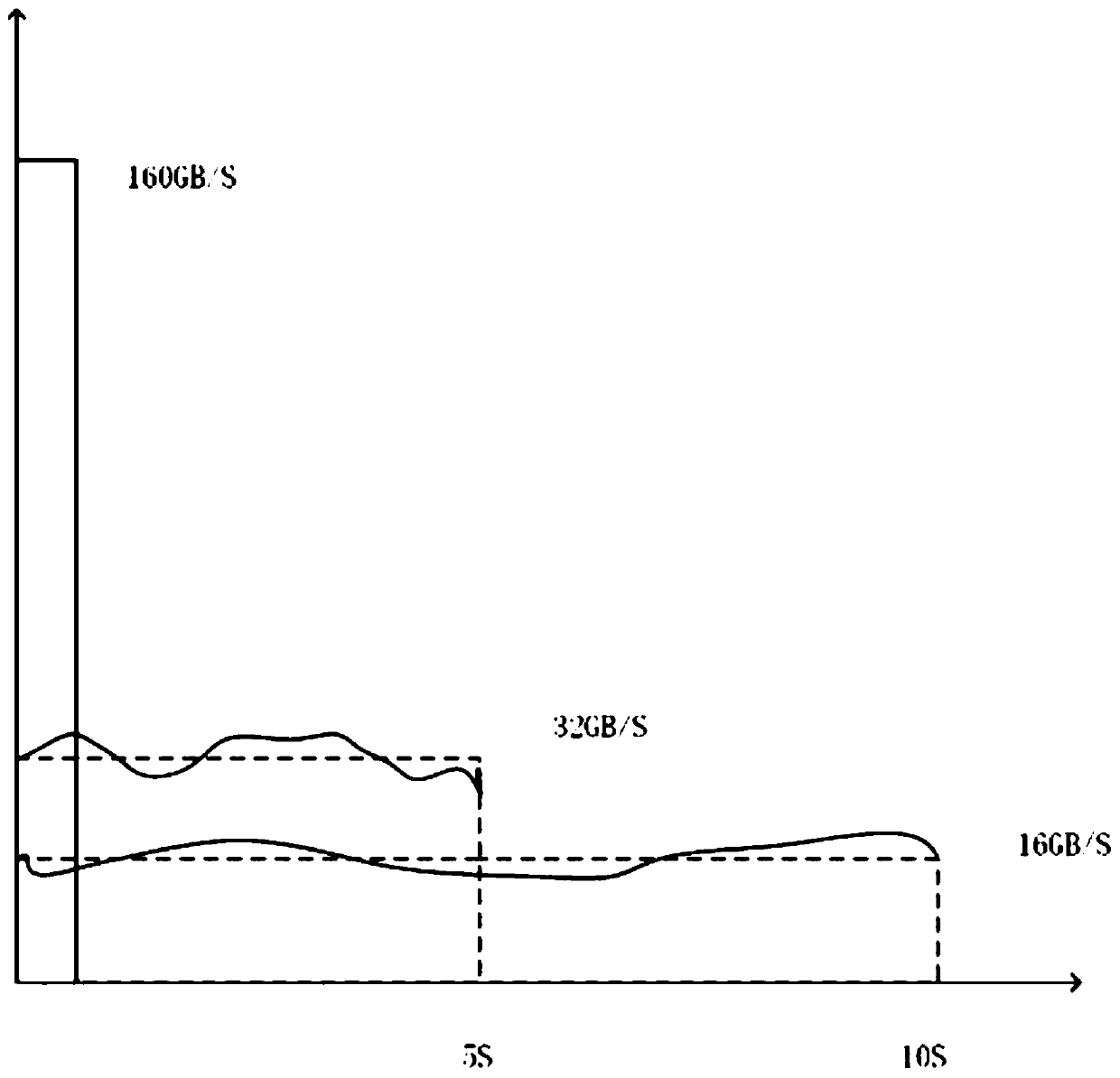
[0075] Such as image 3 As shown, assume that the total bandwidth of the I / O subsystem is 100GB / s, and there are a total of 16,000 nodes to write checkpoint files. If the amount of checkpoint data written by each node is 10MB, regardless of I / O Under the ideal environment of conflict, it takes 160GB / s to finish writing within 1s; if the delay is 5s, then an average of 32GB / s needs to be written within 5s; if the delay is 10s, only 16G / s needs to be written per second. Occupancy drops below the total system bandwidth. However, the actual writing time should be longer than the theoretical time, because a large number of simultaneous writing causes conflicts and reduces I / O efficiency, and the degree of such conflicts decreases as the delay time increases.
[0076] exist Figure 4 When the delay time shown is 0, it means that the random delay writing method is not used. When the delay time begins to increase, the total write time shows a downward trend due to the reduction of ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More