

Video semantic representation method and system based on multi-mode fusion mechanism and medium
A multi-modal and video technology, applied in neural learning methods, computer components, character and pattern recognition, etc., can solve problems such as multi-modal heterogeneous gaps, difficulty in feature extraction of characterization video data, and semantic gaps
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0073] It should be pointed out that the following detailed description is exemplary and intended to provide further explanation to the present application. Unless defined otherwise, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this application belongs.
[0074] It should be noted that the terminology used here is only for describing specific implementations, and is not intended to limit the exemplary implementations according to the present application. As used herein, unless the context clearly dictates otherwise, the singular is intended to include the plural, and it should also be understood that when the terms "comprising" and / or "comprising" are used in this specification, they mean There are features, steps, operations, means, components and / or combinations thereof.
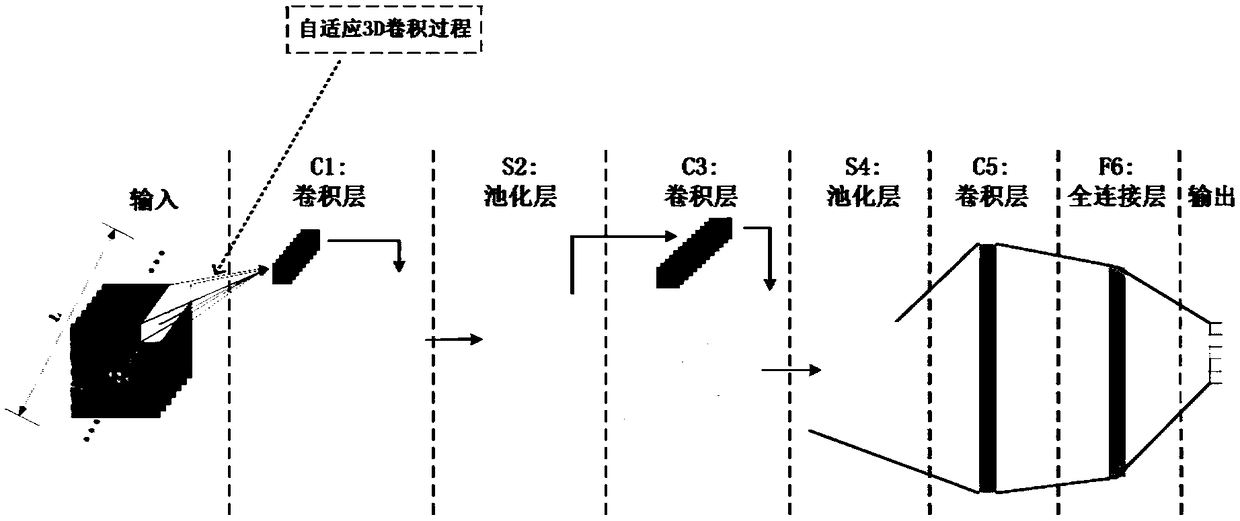
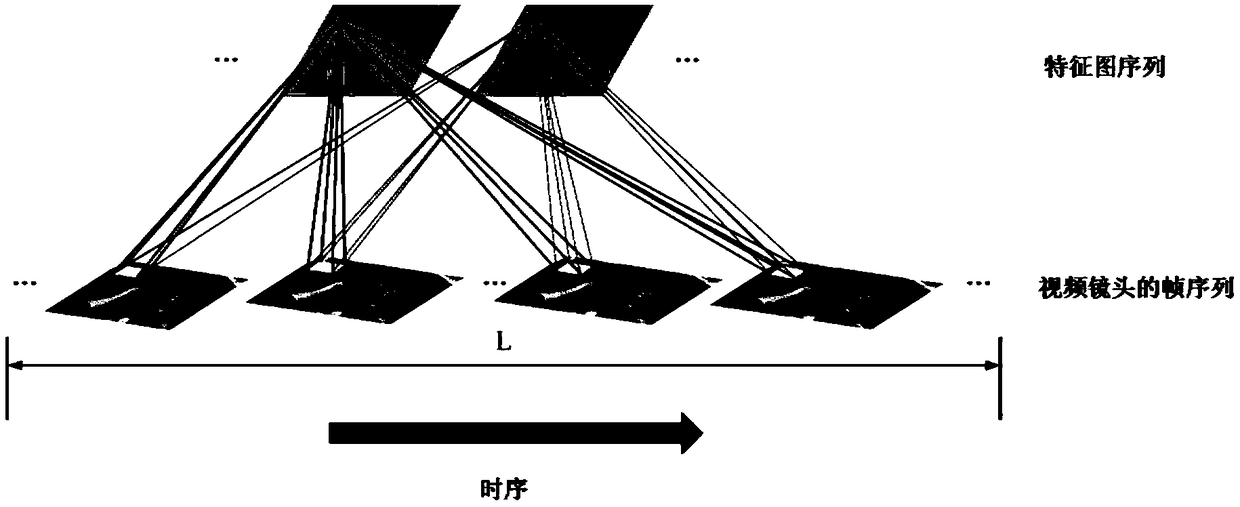
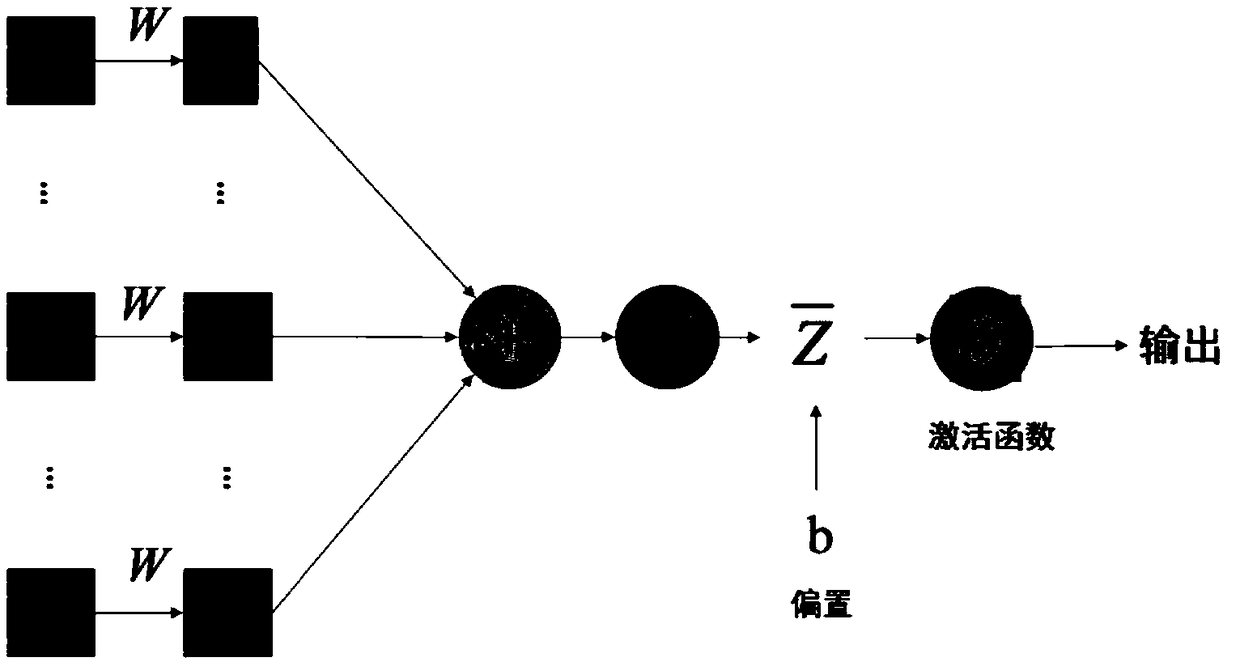
[0075] The disclosure first proposes a spatio-temporal feature learning model of an adaptive frame selection mec...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More