

Intelligent voice interaction system and method thereof
An interactive system and intelligent voice technology, applied in voice analysis, voice recognition, voice input/output, etc., can solve the problems of voice recognition word limit, reduced fun, low recognition rate, etc., to achieve fast data processing speed, voice interaction The effect of being friendly and recognizing a wide vocabulary
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
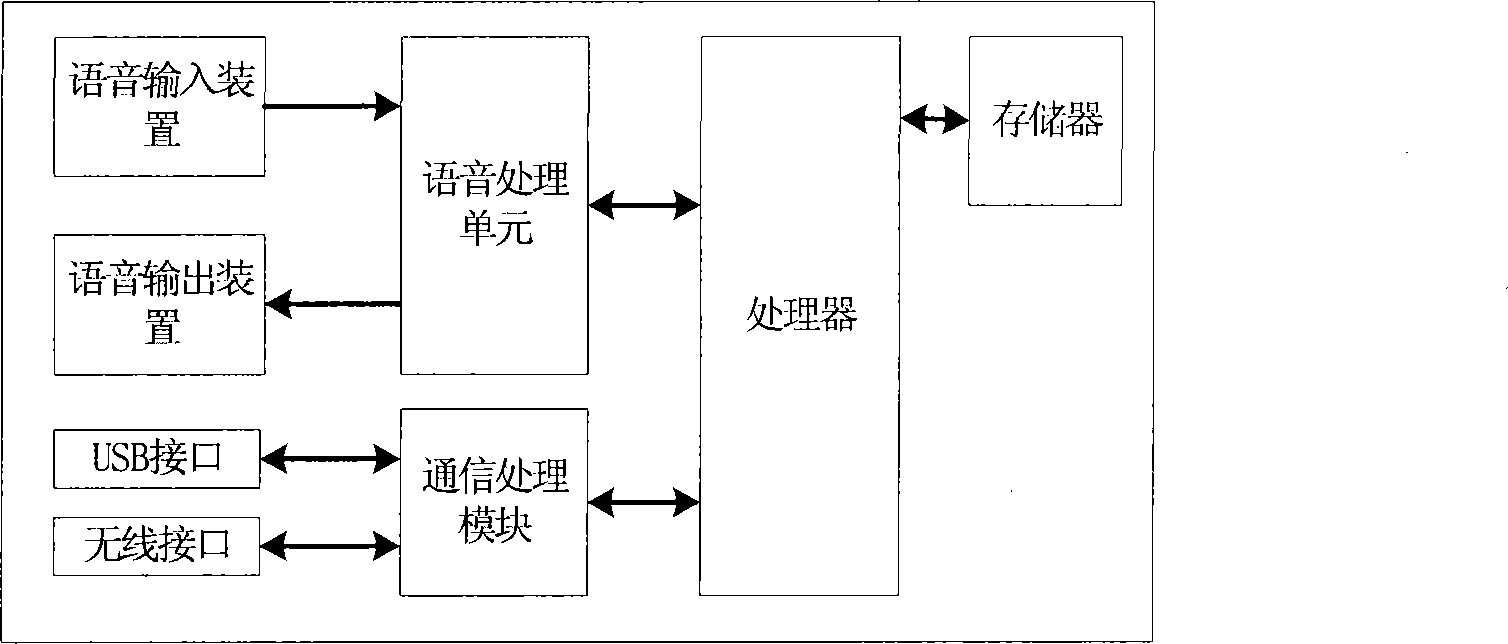
[0057] Such as figure 1 As shown, the present embodiment provides a voice intelligent system for smart toys, which can be applied to various voice platforms to realize voice interaction, such as voice intelligent toys, robots, man-machine dialogue systems, etc., the specific structure is as follows figure 1 shown, including:
[0058] The processor, memory, voice processing unit and communication processing unit are all arranged on the circuit board, and the memory, voice processing unit and communication processing unit are connected to the processor through the bus to form an embedded control board;
[0059] Voice input device, voice output device are respectively connected with the described voice processing unit on the embedded control board;
[0060] The communication processing unit is provided with a communication interface, and the communication interface is connected to a computer installed with custom client software.
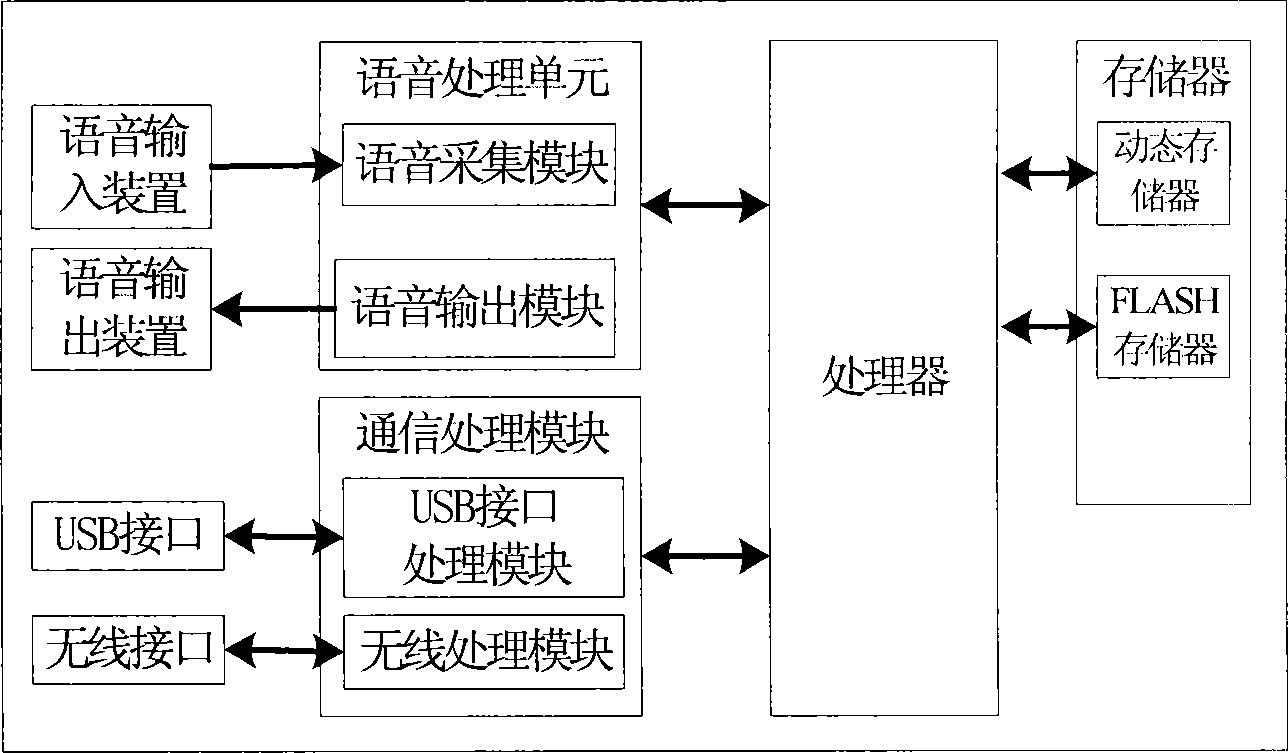
[0061] Wherein, the memory includes: a dynamic...
Embodiment 2
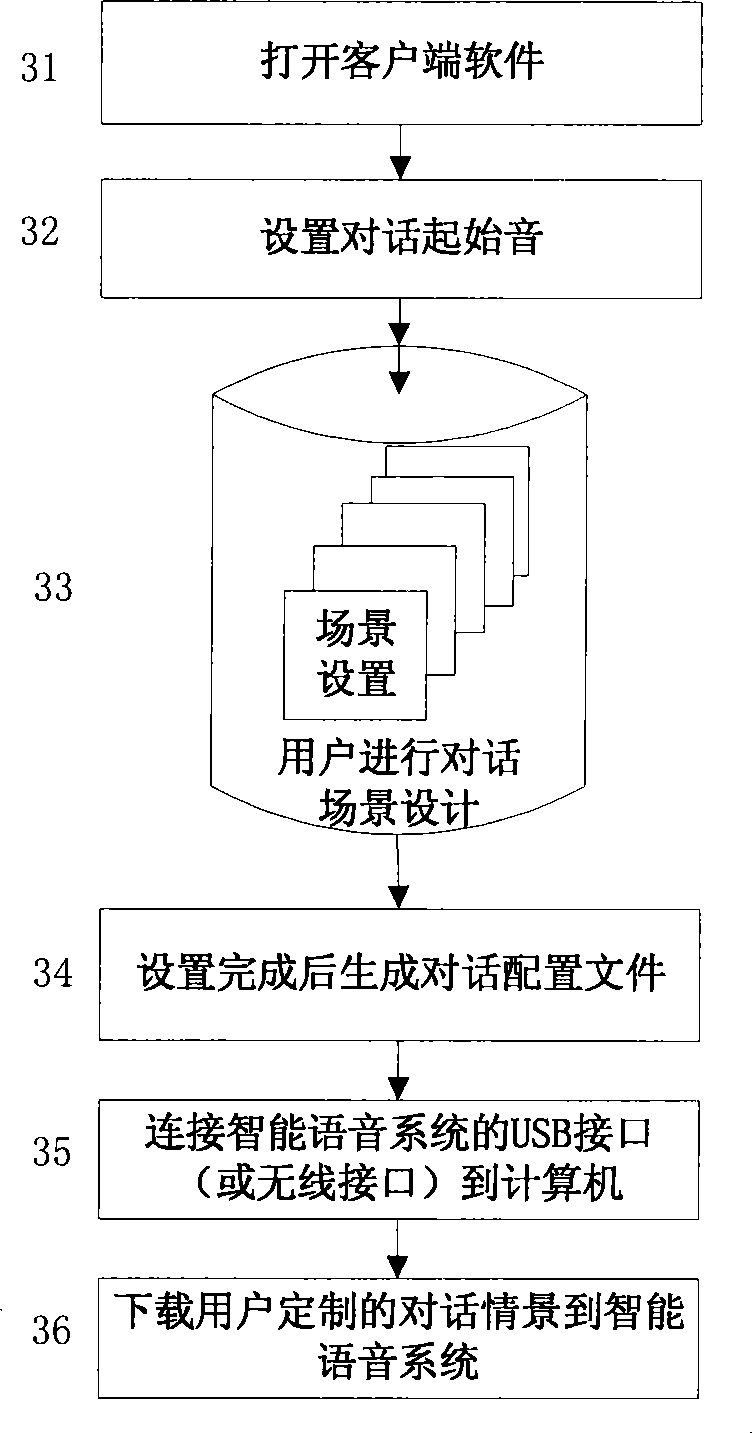
[0069] This embodiment provides an interactive method based on the voice intelligence system of the smart toy in Embodiment 1, the method comprising:
[0070] After the system starts, through the control of the processor, the speech recognition module and the speech library module stored in the FLASH memory are loaded into the dynamic memory. In practice, these two modules are in the form of software, such as speech recognition based on HMM engine;
[0071] The external voice command is entered by the voice input device, and the analog voice signal of the external voice command is converted into a digital voice signal by a voice processing unit (such as by a voice acquisition chip in the voice processing unit);
[0072] The digital sound signal is sent to the processor, and the processor calls the speech recognition module in the dynamic memory simultaneously, and compares the pronunciation characteristics of the speech pronunciation feature library in the speech recognition e...
Embodiment 3
[0093] In this embodiment, the intelligent voice system and its interaction method of the present invention are further described through a specific implementation process, such as Figure 6-13 As shown, the system is divided into two aspects: software and hardware, including:
[0094] (1) Hardware part:
[0095] The hardware is based on the ARM9 high-performance SOC processor S3C2410, the main frequency is 200Mhz, and the ARM9 SC2410 embedded controller is the center, through the external microphone sensor to complete the collection of voice signals, the sampling, amplification and pre-filtering of voice signals and the subsequent voice The playback is completed by the audio chip WM8731. The board is equipped with 32×16bit extended SDRAM storage space and 64M×16bit NAND Flash storage space. The system uses the USB interface to communicate with the client interface of the user application development layer. In this system, the USB interface is taken as an example to illustrat...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More