

Power grid peak load clustering extraction method based on Pearson coefficient and MapReduce parallel computing
A parallel computing, peak load technology, applied in computing, computer components, electrical and digital data processing, etc., can solve problems such as poor clustering effect and slow operation speed
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

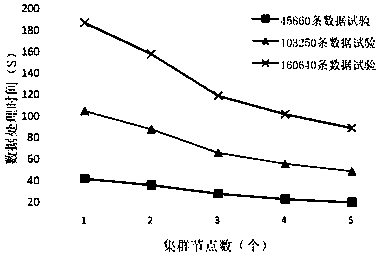
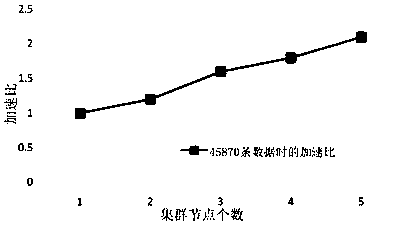
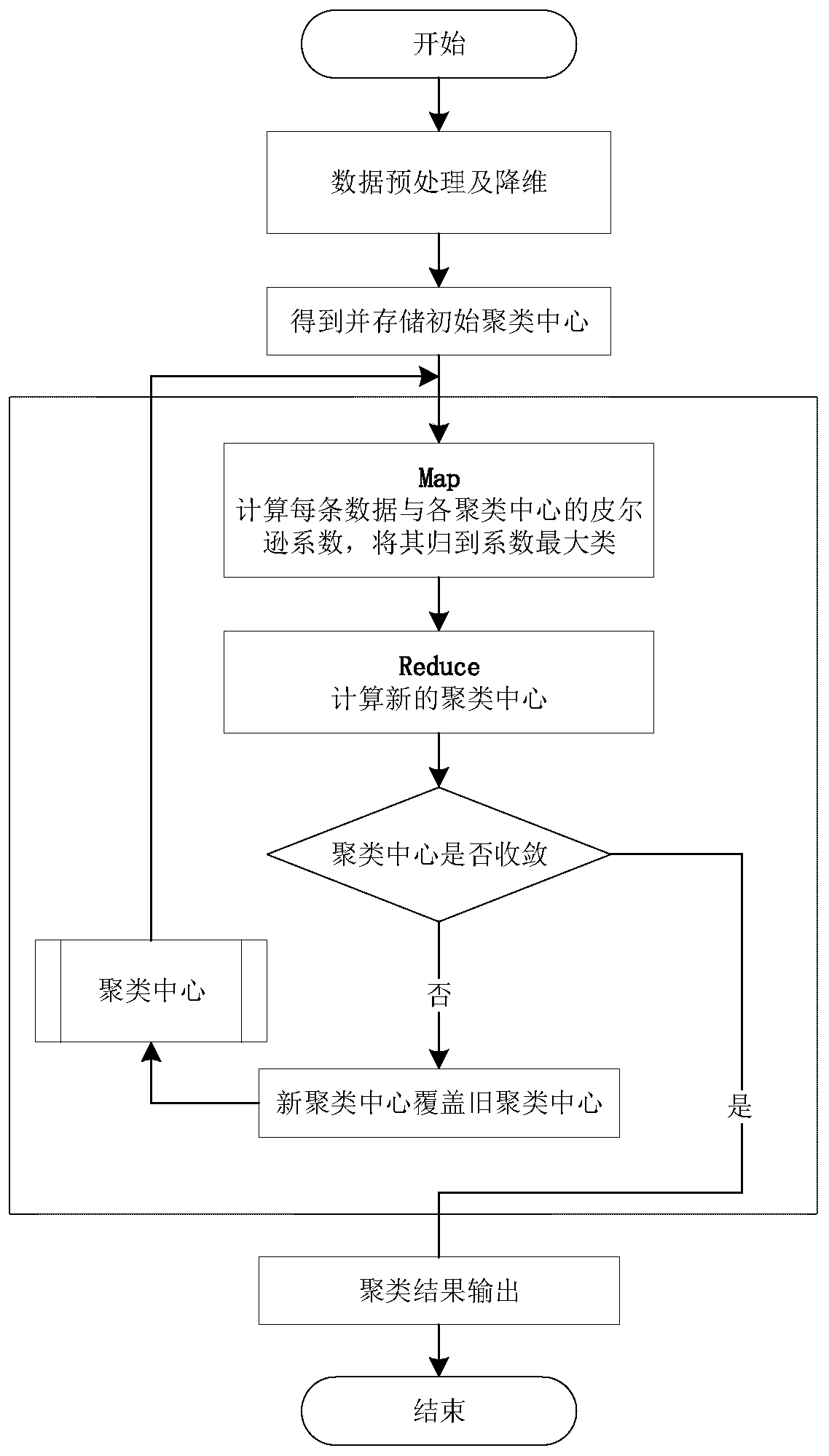
Examples
Embodiment Construction
[0080] Specific embodiments of the present invention will be described below in conjunction with the accompanying drawings, so that those skilled in the art can better understand the present invention.
[0081] In order to achieve the above-mentioned purpose of the invention, a network peak load clustering extraction algorithm based on Pearson coefficient and MapReduce parallel calculation of the present invention is characterized in that it comprises the following steps:
[0082] Data acquisition and preprocessing:
[0083] By collecting historical data, preprocessing the collected data, cleaning abnormal data, taking into account the sudden increase or drop of load power, when the difference between adjacent points of the load curve power is large, use Neville based on Lagrange interpolation Algorithm pair curve X={x 1 ,x 2 ,...,x n} Perform interpolation repair, denoise the data, and finally form a sample data set that can be used for load forecasting;
[0084] Dimensio...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More