[0005] However, because the existing content-based image retrieval methods cannot fully satisfy users, with the development of
statistical learning methods and the theory and technology of
big data association, content-based image retrieval methods have great room for
performance improvement , the existing problems and areas that need to be further improved are mainly manifested in the following aspects:
[0006] First, the accuracy rate of image retrieval is low. There is almost no image retrieval
system in the existing technology that can achieve a satisfactory level of accuracy. When querying and retrieving images, the user still has hundreds of images returned It takes a lot of time to screen;
[0007] Second, the degree of interaction with users is not enough. In many application fields, users need to actively participate and give feedback, because pictures belonging to different categories will have different characteristics. At this time, different algorithms need to be designed to target different picture characteristics. At the same time, users also hope to have more freedom in selective extraction and similar matching algorithms;
[0008] Third, the correlation between semantic features and low-level features is not enough. The existing technology has made a lot of characters in the low-level features of pictures, but there are still some problems. Large limitations do not solve the problem fundamentally. In addition, manual participation can improve the retrieval effect, but it also increases the time spent on retrieval, which is not conducive to real-time retrieval
[0009] Fourth, with the
rapid expansion of Internet information today, Internet retrieval has entered the image retrieval stage with more vivid content and broader meaning. The development of image retrieval methods has stimulated
the Internet industry to continuously launch related products, and the development of the industry requires further The development of related technology constantly puts forward new requirements. The existing image retrieval is mainly used in specific databases, which has not yet met all the intelligent retrieval requirements. For large-scale image data, it is impossible to effectively retrieve the required images. Unable to apply user feedback techniques to obtain more satisfactory results
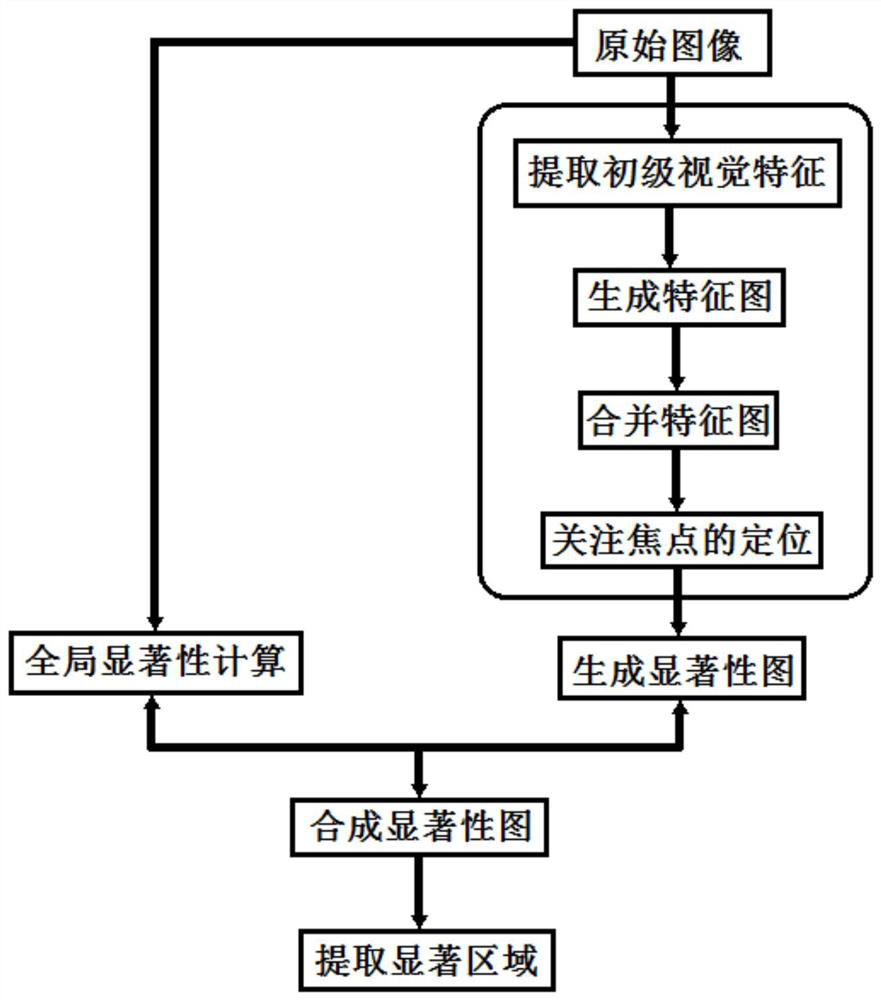
[0010] Fifth, the local feature-based method in the prior art has attracted widespread attention. This retrieval method divides the image into a certain number of local feature points, and then extracts the corresponding features. Image region segmentation is the basic step of region-based image retrieval, but Segmentation without prior knowledge of
image segmentation is a very difficult task. When there are a large number of target objects to be segmented or no clear targets in the scene, this task will become more difficult. Existing techniques extract Although the
salient point method has its advantages, it takes a lot of time due to the low efficiency of the
salient point detection operator. In addition, it is impossible for the detection operator to fully describe the complex content of the picture, and it is impossible to fully reproduce a certain type of picture by using the
point set. area of most interest
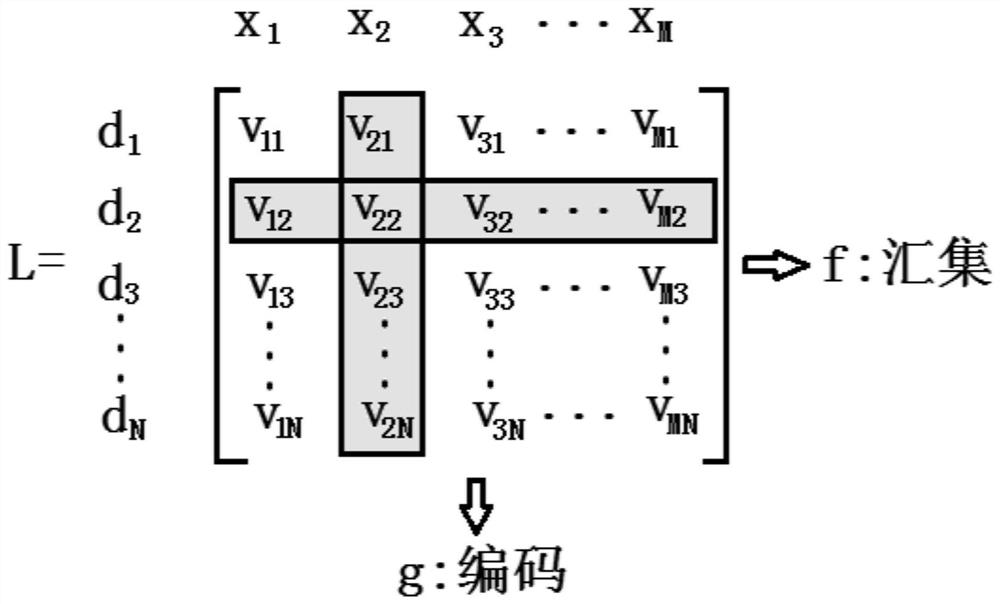
Most of the existing technical methods are learning theories when there are a large number of samples. Because it is difficult to obtain a large number of learning samples in practical applications, the effect is often not ideal, and some algorithms have relatively high computational complexity.
[0011] Sixth, the existing
support vector machine model is often used in user feedback, but the average accuracy of the feedback
system based on SVM cannot achieve the expected effect, mainly because the
SVM classifier is unstable when the number of
positive feedback samples is small , the optimal hyperplane of SVM is very sensitive to a small number of samples, and users often mark a small number of pictures when giving feedback, and at the same time cannot guarantee that all samples are fully and accurately marked, so when the samples are insufficient and the marks are inaccurate, SVM is very difficult It is difficult to achieve better results. In addition, when the number of positive samples is less than that of negative samples, the obtained hyperplane will also produce deviations. In this case, it is easy to feed back negative samples into positive samples. The number of training samples may It will be lower than the dimension of the
feature vector, which is also easy to cause
small sample problems in this case;
[0012] Seventh, there is no retrieval method in the prior art that can achieve satisfactory results on all pictures. Based on this basic
cognition, the present invention analyzes the main problems existing in the process of image retrieval in the prior art from the perspective of
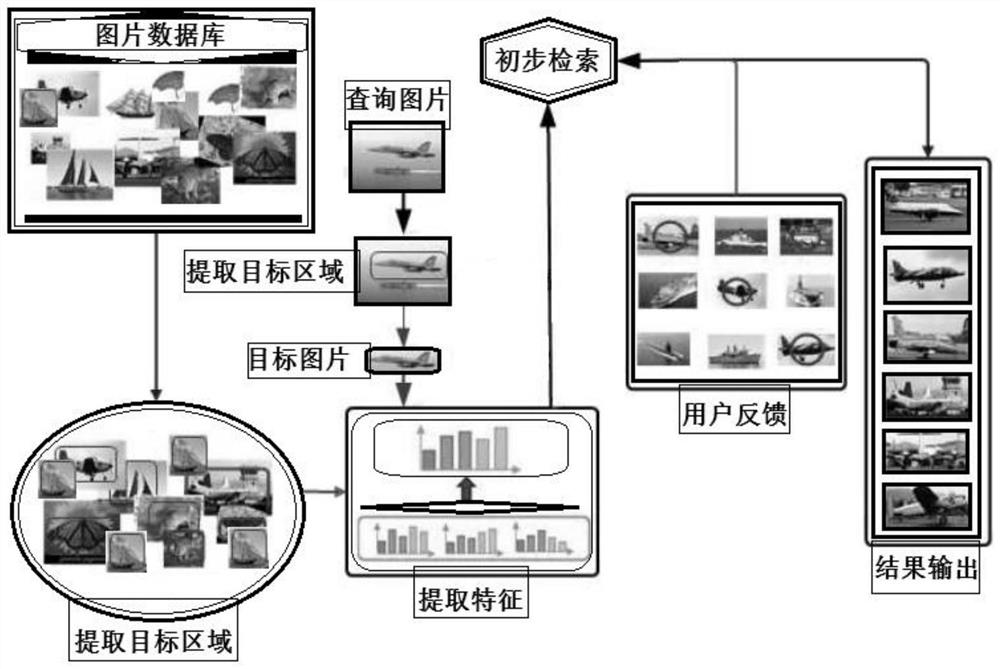
user needs It includes two points: first, it is impossible to locate the user's interest area accurately enough, and the extracted image target deviates from the user's attention area; second, it is impossible to accurately retrieve the target image that really meets the user's needs



 Login to View More
Login to View More  Login to View More
Login to View More