

Biological sequence data-base searching multilayered accelerating method based on flow process
A biological sequence and database technology, which is applied in the field of multi-level acceleration of biological sequence database search based on stream processing, and can solve problems such as searching of biological sequence databases that have not been seen before.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0090] specific implementation plan
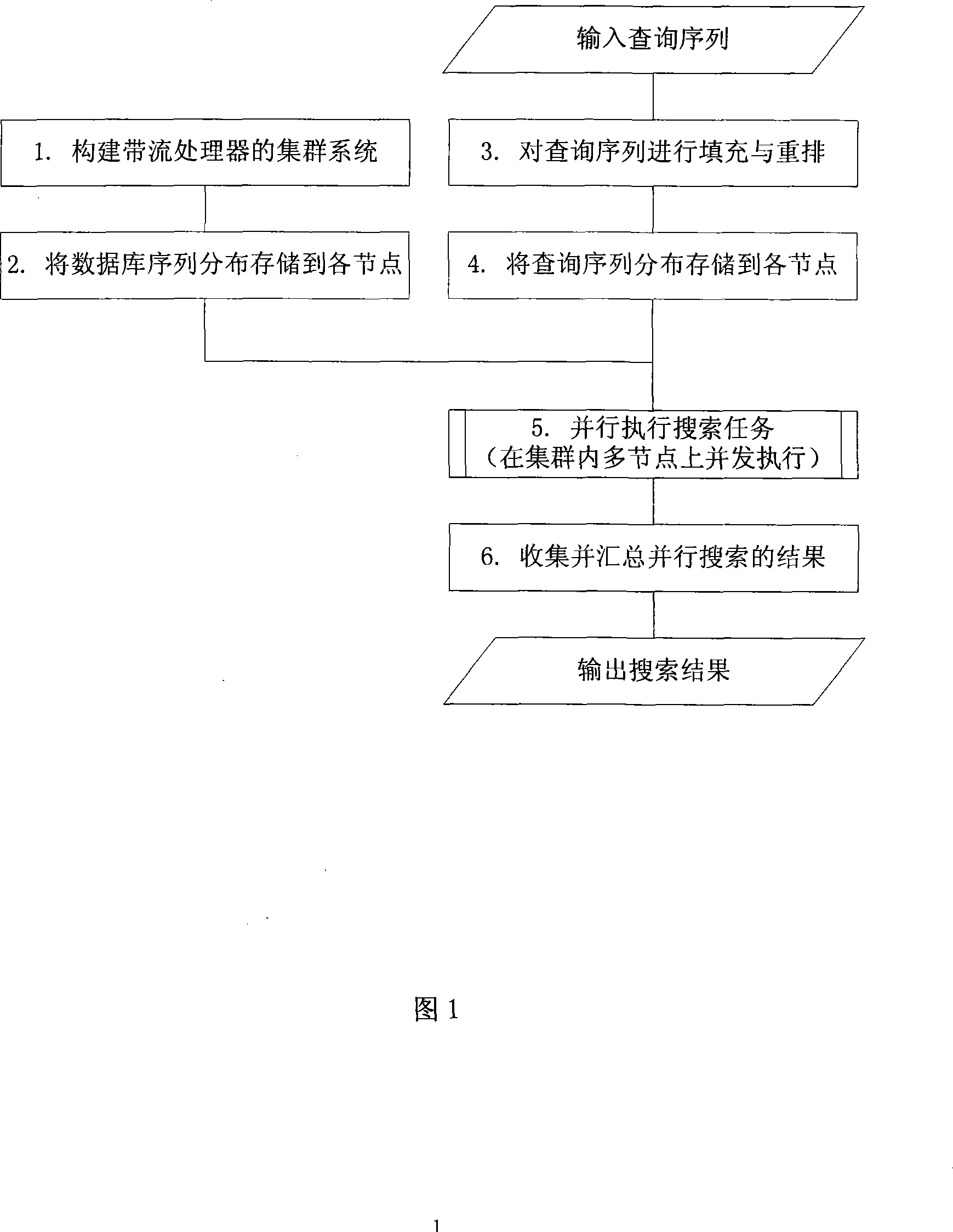
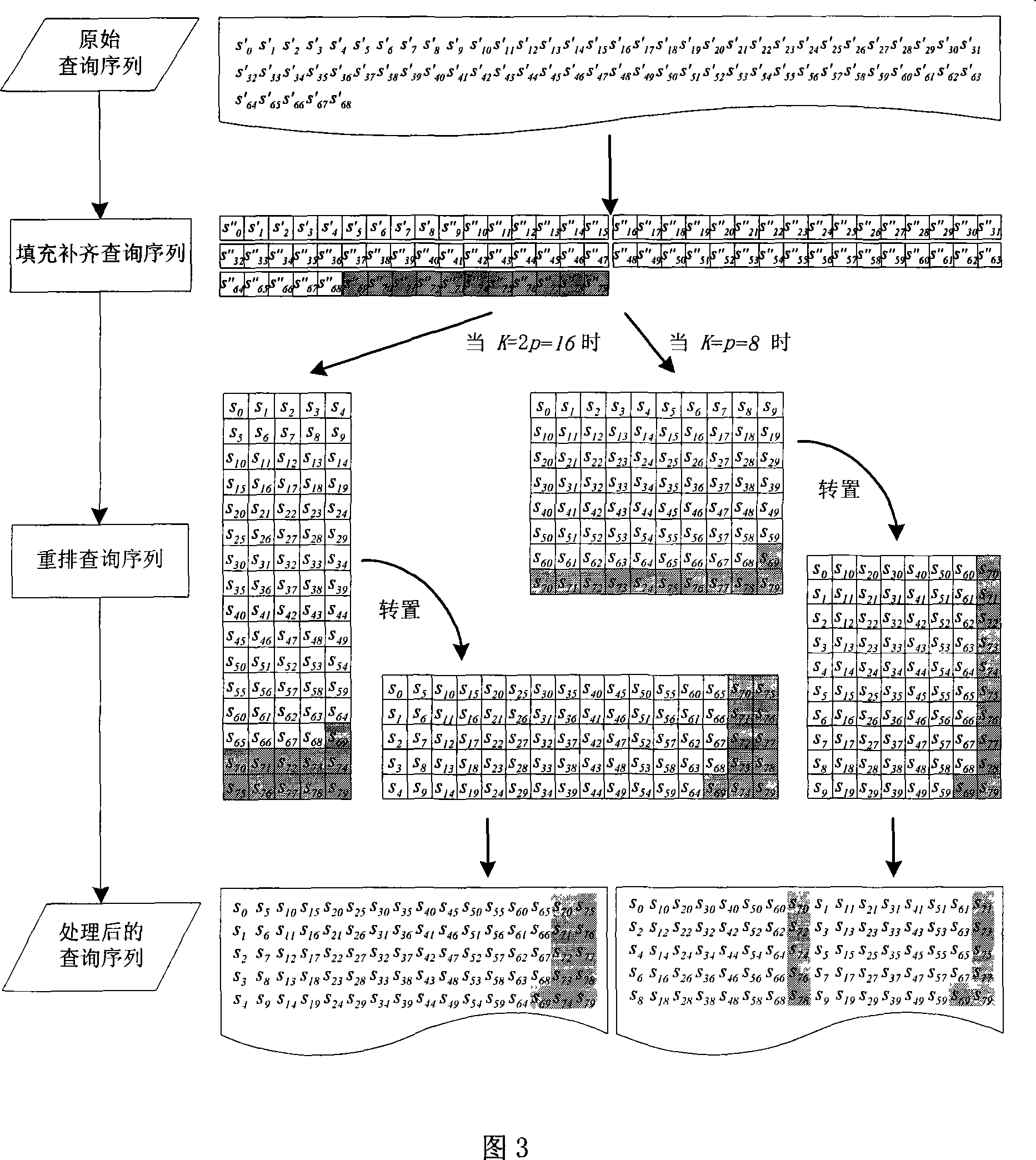
[0091] Fig. 1 is the general flow chart of the present invention, mainly comprises following six steps, and wherein the 1st~2 steps are the establishment of cluster system and the preprocessing of database sequence, only need to carry out once when system is established at the beginning and database has update, In each subsequent specific task of searching the database, only steps 3 to 6 need to be performed.
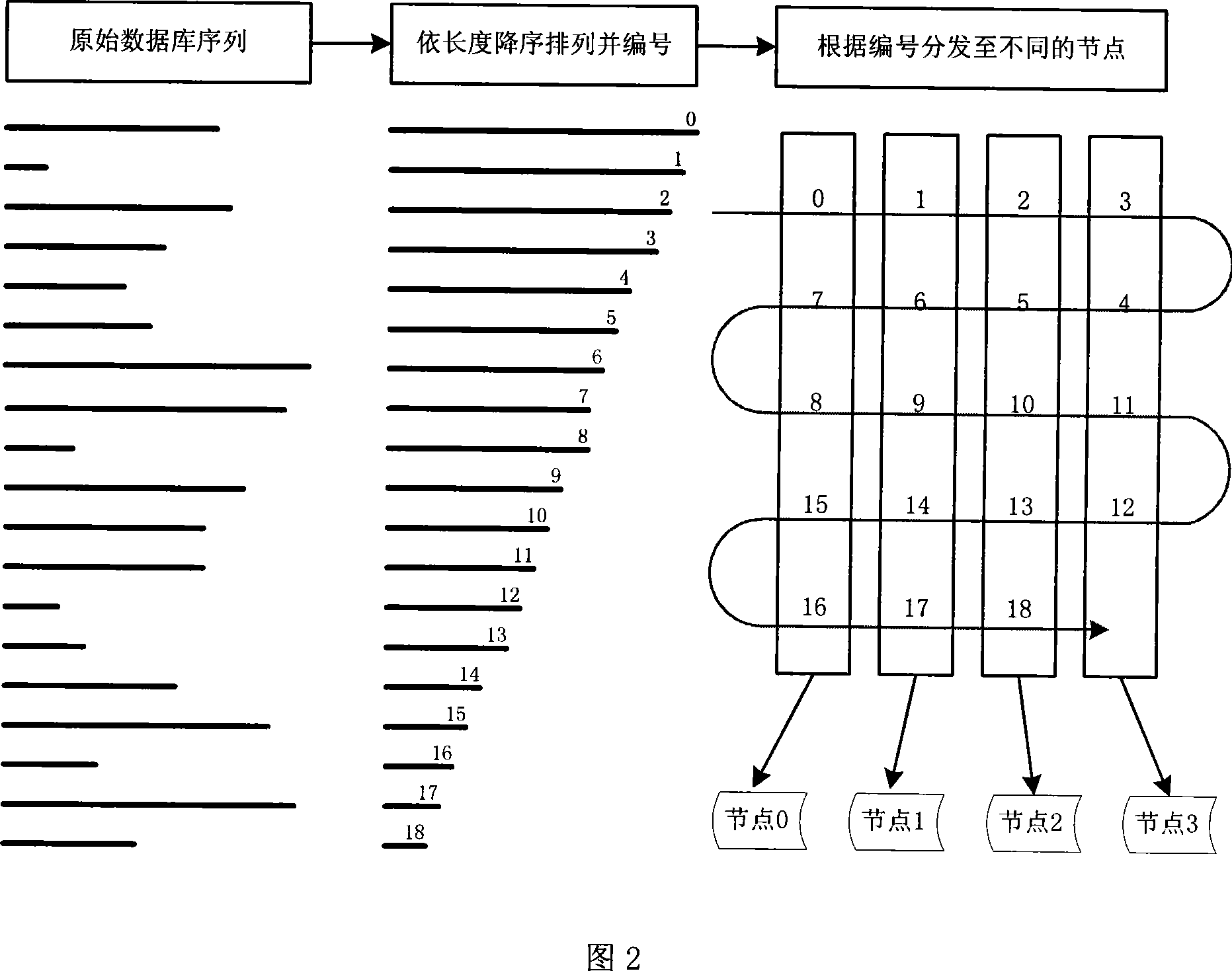
[0092] 1. Build a cluster system with a stream processor. The cluster system is composed of multiple personal computers, each of which is a node of the cluster system, and each node has its own independent storage system, and the communication between nodes adopts the way of message transmission. Nodes are sequentially numbered 0, 1, 2, ..., n p -1. here n p is the total number of nodes in the cluster system (in the actual system, n p The value of is an integer power of 2, etc.). In order to facilitate subsequent processing, t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More