Currently, the devices widely used in industry for obtaining 3D measurements involve the mechanical scanning of a scene, for example in a
laser scanning digitizer, which inevitably makes the measurement a slow process.
However, the existing systems lack the ability to change their settings, to calibrate by themselves and to reconstruct the 3D scene automatically.
The first issue is how to acquire the 3D data for reconstructing the object surface.
However, due to the mechanical scanning involved, the acquisition speed is limited.
The second issue is how to determine the next viewpoint for each view so that all the information about the object surface can be acquired in an optimal way.
In general, there are two fundamental problems to be solved when determining the Next Best View.
The first problem is to determine the areas of the object which need to be sensed next and the second is to determine how to position the sensor to sample those areas.
As there is no prior knowledge about the object, it is impossible to obtain a complete description of an object when
occlusion occurs.
Therefore, it is not generally possible to obtain precisely the invisible portions from either the current viewpoint or the acquired partial description of the object, so only an
estimation of the Next Best View may be derived.
This
algorithm is computationally expensive and it does not incorporate the sensor geometry.
However, this solution is limited to a particular sensor configuration.
However, the superellipsoid cannot accurately represent objects with a complex
surface shape.
The
algorithm involves expensive computation on the
solid modeling and intersection operation.
A traditional
vision sensor with fixed structure is often inadequate for the
robot to perceive the object's features in an uncertain environment as the
object distance and size are unknown before the
robot sees the object.
This assumption limits the range of applications of this method.
How to obtain a suitable initialization was still an issue to solve [31].
As a result, they suffer from the
ambiguity of correspondences between the camera images, which is a difficult problem to solve especially when free-form surfaces [33] are involved in the scene.
As a result, the applications of
active vision systems are limited, since the
system configuration and parameters must be kept unchanged during the entire measurement process.
The available camera self-calibration methods cannot be applied directly to structured-light systems as they need more than two views for the calibration.
The limitation of this method is that the object must be placed on a special device so that it can be precisely moved.
In such applications, uncalibrated reconstruction is needed.
However, it was not clear how many of the parameters of the camera and
projector could be self-determined in the uncalibrated reconstruction process.



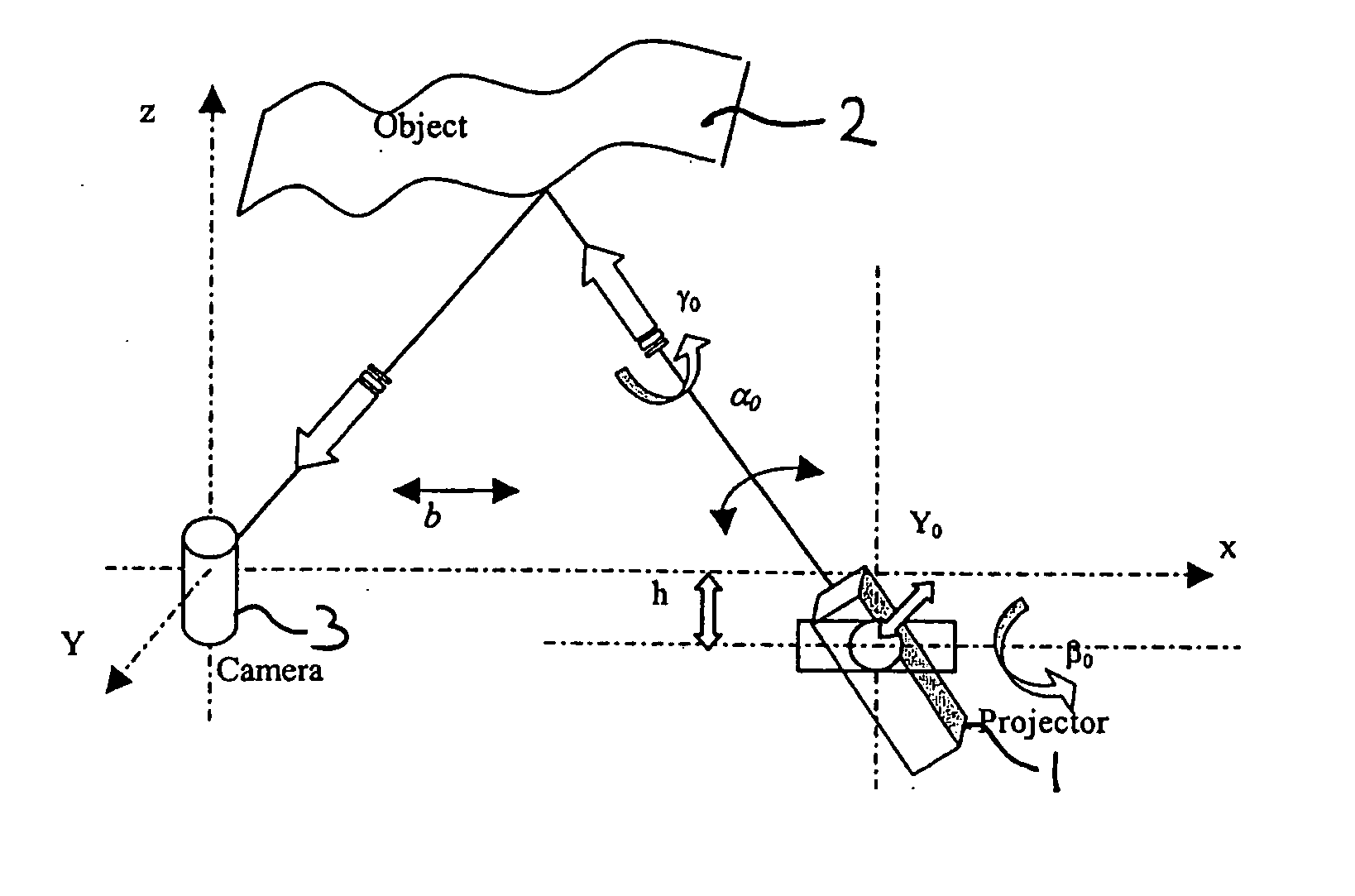
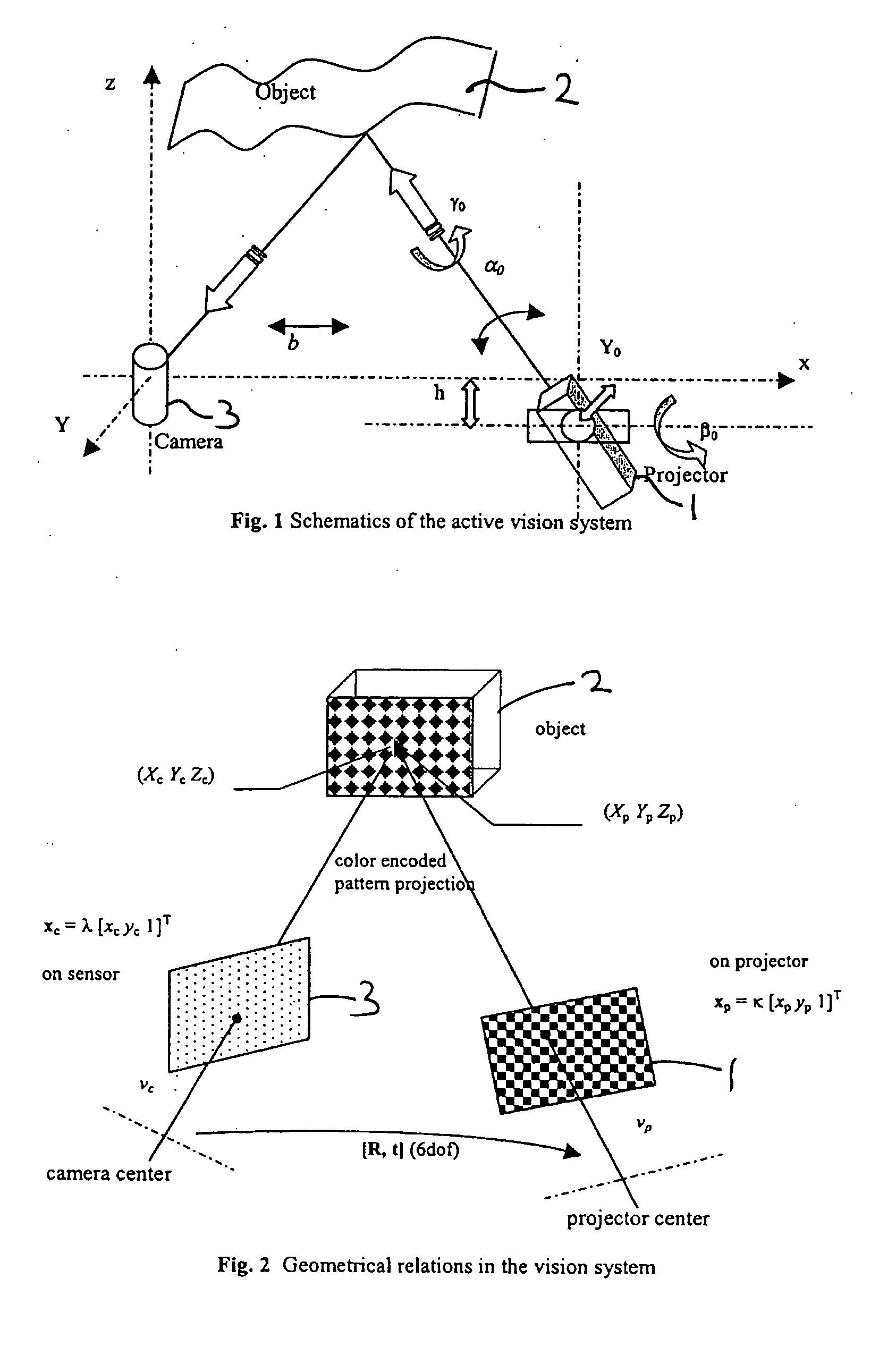
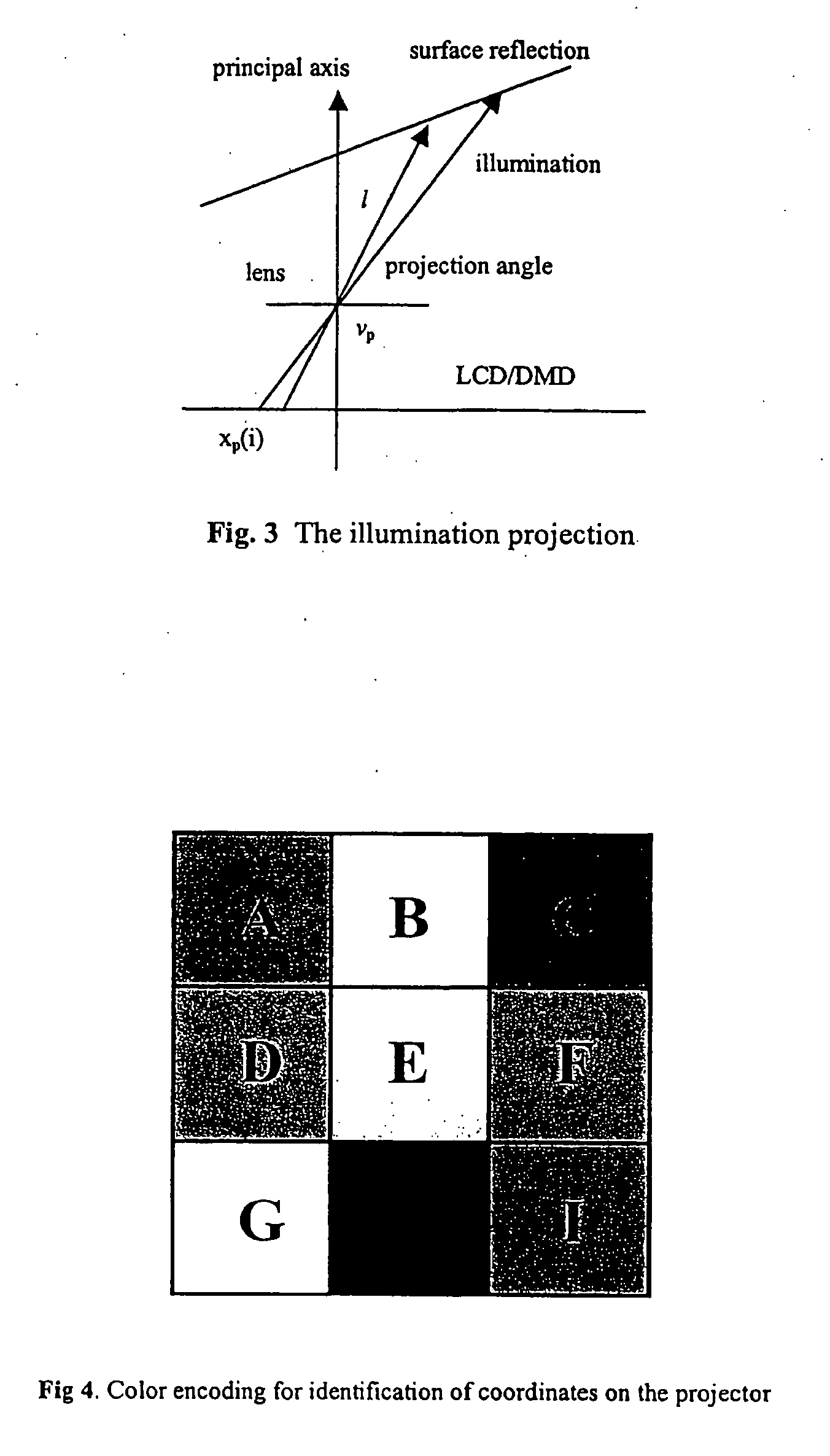
 Login to View More
Login to View More  Login to View More
Login to View More