

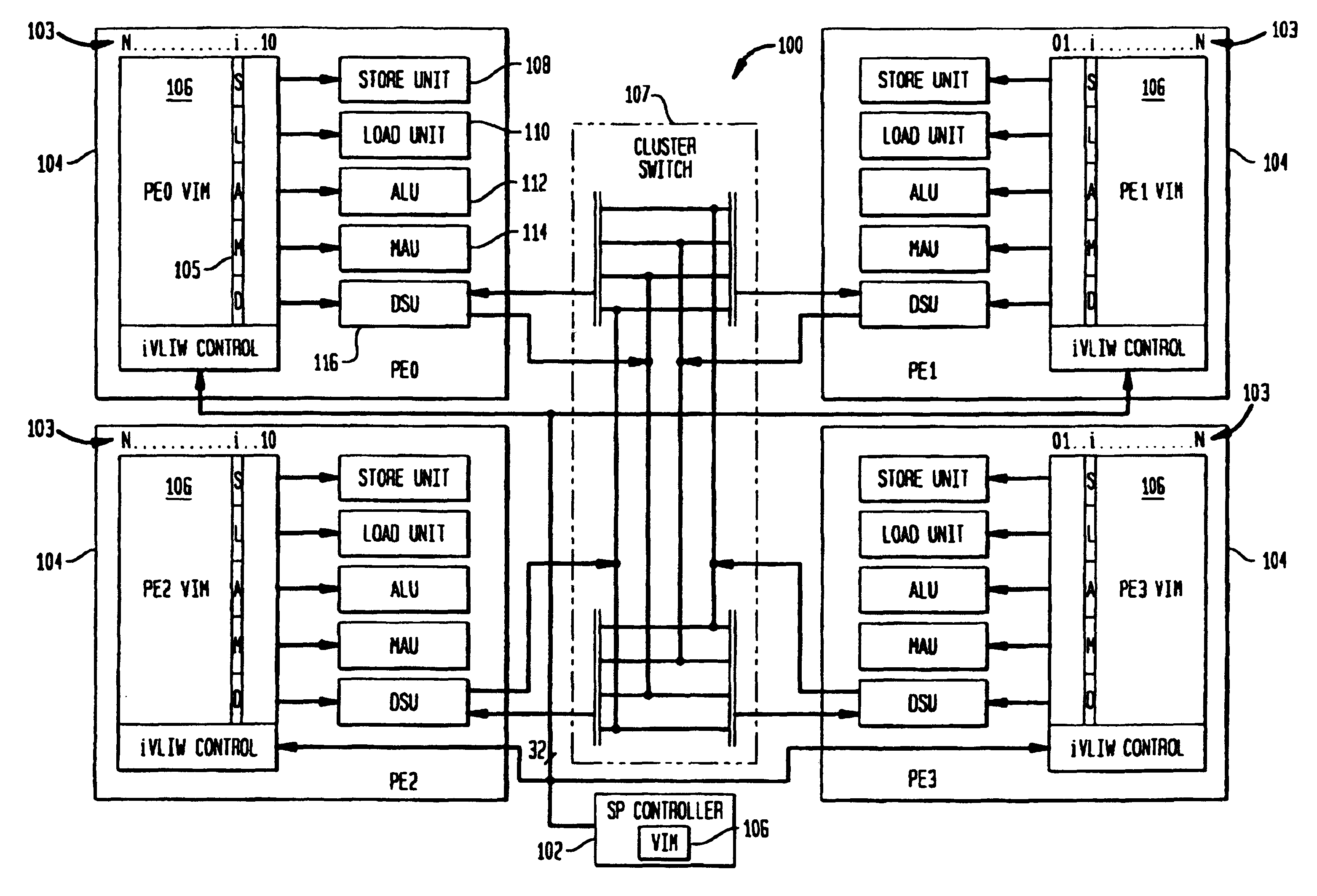
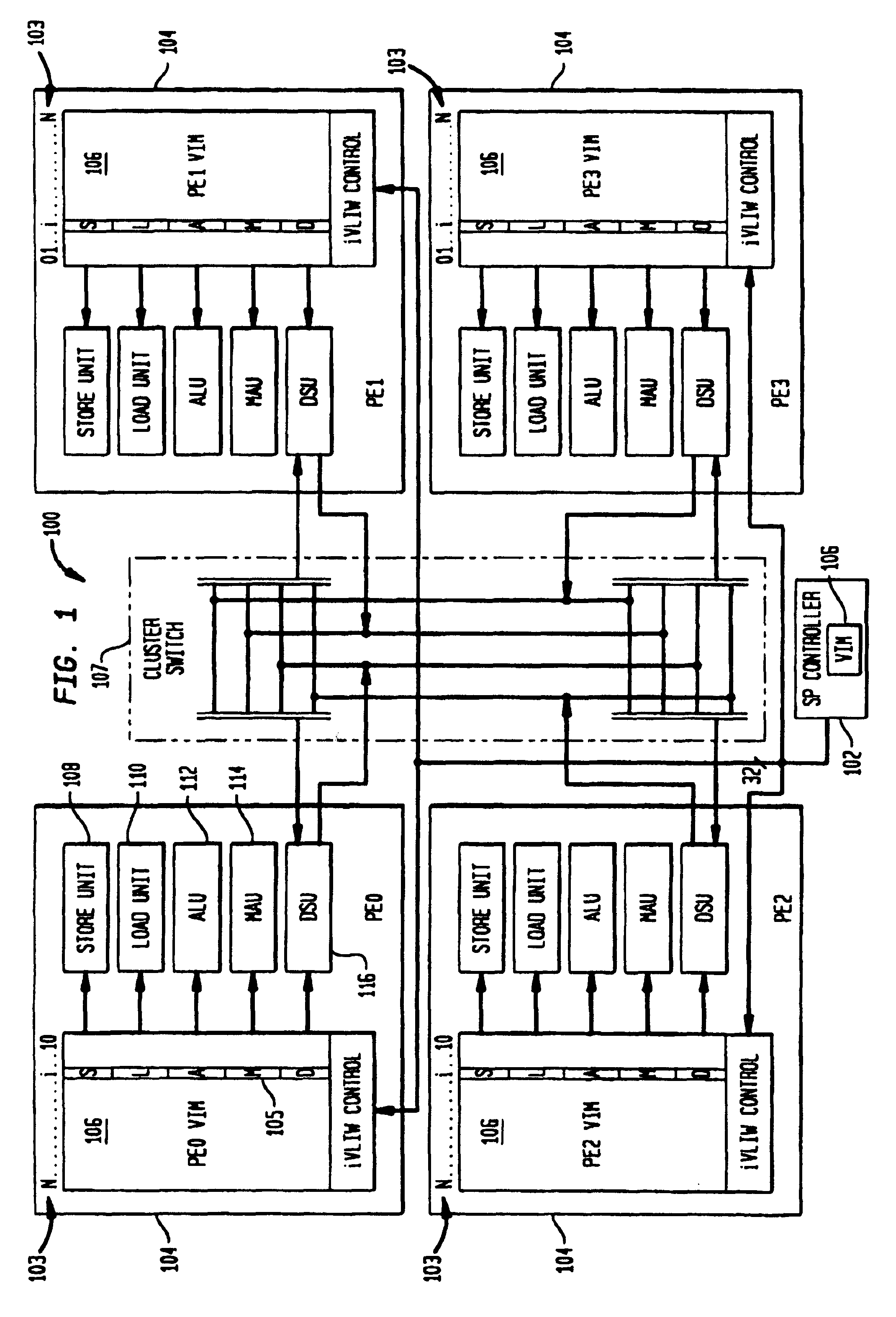
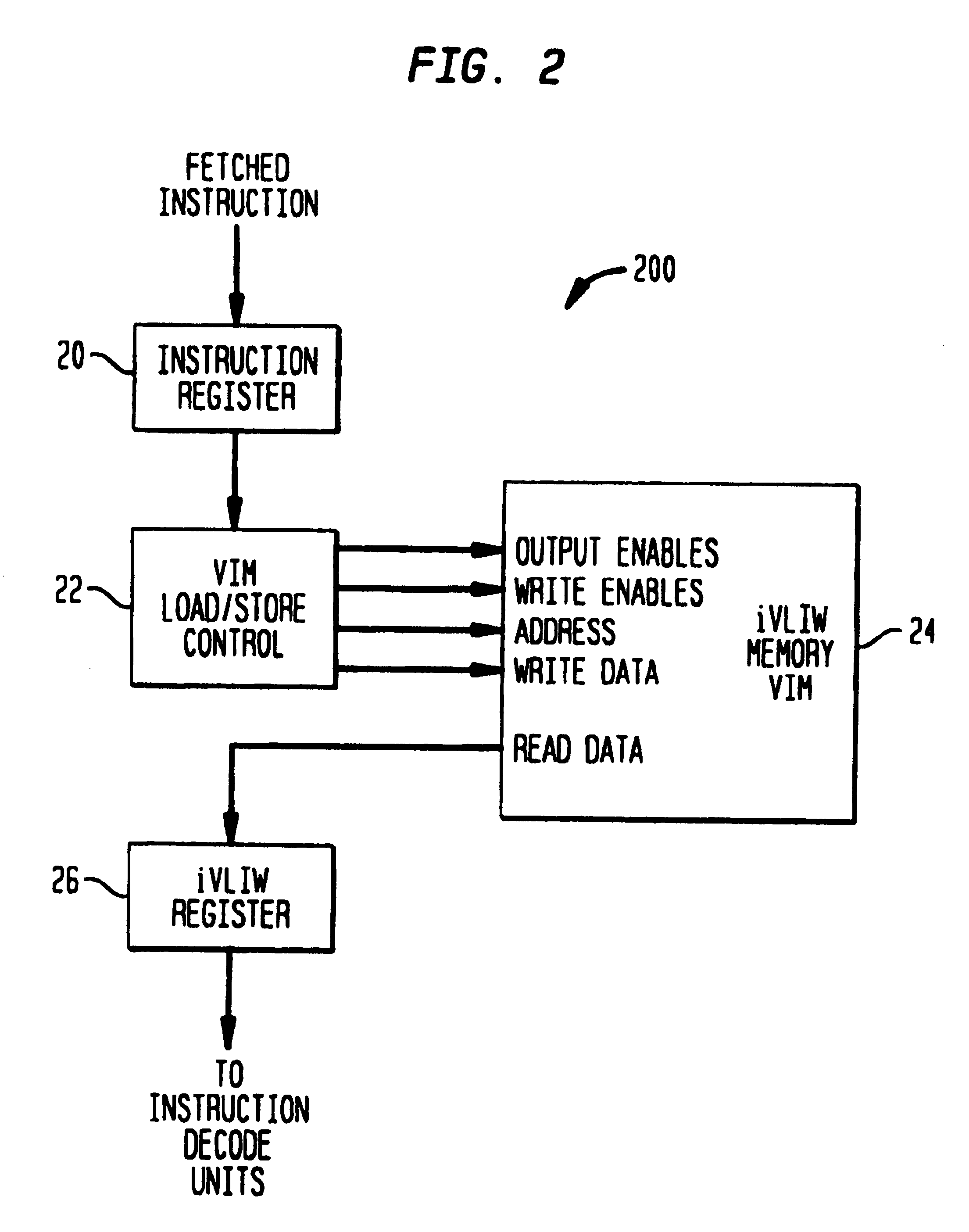
Methods and apparatus for efficient synchronous MIMD operations with IVLIW PE-TO-PE communication
a technology of synchronous mimd and ivliw, which is applied in the direction of program control, instruments, and multiple processing units, can solve the problems of not all algorithms can make efficient use of the available parallelism existing in the processor, and the difficulty of efficiently synchronizing processors to cooperate,
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
example 1-1
Loading Synchronous MIMD iVLIWs into PE VIMs
[0063]
! first load in instructions common to PEs 1, 2, 3lim.s.h0 SCR1, 1! mask off PEO in order to load in 1, 2, 3lim.s.h0 VAR, 0! load VIM base address reg v0 with zerolv.p v0, 27, 2, d=, f=! load VIM entry v0+27 (=27) with the! next two instructions; disable no! instrs; default flag setting to ALU li.p.w R1, A1+, A7! load instruction into LU fmpy.pm.1fw R6, R3, R31! mpy instruction into MAUlv.p v0, 28, 2, d=, f=! load VIM entry v0+28 (=28) with the! next two instructions; disable no! instrs; default flag setting to ALU li.p.w R2, A1+, A7! load instruction into LU fmpy.pm.1fw R4, R1, R31! mpy instruction into MAUlv.p v0, 29, 2, d=, f=! load VIM entry v0+29 (=29) with the! next two instructions; disable no! instrs; default flag setting to ALU li.p.w R3, A1+, A7! load instruction into LU fmpy.pm.1fw R5, R2, R31! mpy instruction into MAU! now load in instructions unique to PEOlim.s.h0 SCR1, 14! mask off PEs 1, 2, 3 to load PEOnop...
example 1-2
Executing Synchronous MIMD iVLIWs from PE VIMs
[0064]
! address register, loop, and other setup would be here. . .! startup VLIW execution! f= parameter indicates default to LV flag settingxv.p v0, 27, e=l, f=! execute VIM entry V0+27, LU onlyxv.p v0, 28, e=lm, f=! execute VIM entry V0+28, LU, MAU onlyxv.p v0, 29, e=lm, f=! execute VIM entry V0+29, LU, MAU onlyxv.p v0, 27, e=lmd, f=! execute VIM entry V0+27, LU, MAU,DSU onlyxv.p v0, 28, e=lamd, f=! execute VIM entry V0+28, all unitsexcept SUxv.p v0, 29, e=lamd, f=! execute VIM entry V0+29, all unitsexcept SUxv.p v0, 27, e=lamd, f=! execute VIM entry V0+27, all unitsexcept SUxv.p v0, 28, e=lamd, f=! execute VIM entry V0+28, all unitsexcept SUxv.p v0, 29, e=lamd, f=! execute VIM entry V0+29, all unitsexcept SU! loop body - mechanism to enable looping has been previously set uploop_begin: xv.p v0, 27, e=slamd, f=! execute v0+27, all units xv.p v0, 28, e=slamd, f=! execute v0+28, all unitsloop_end: xv.p v0, 29, e=slamd, f=! execute v0+2...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More