Method and system for reverse parsing of GPU instruction
An instruction and solver technology, applied in the field of reverse analysis of GPU instructions, can solve problems such as waste of computing resources, low code efficiency, PTX cannot control register allocation, etc., and achieve the effect of improving efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
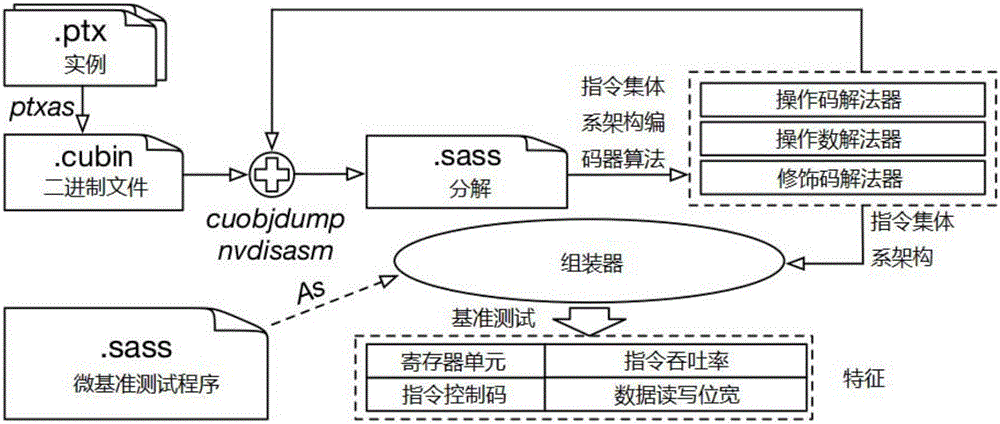
[0031] The following is the instruction parsing algorithm flow of the present invention, as follows:
[0032] Instruction decoding needs to generate the corresponding relationship between 64-bit instruction encoding and assembly instructions, such as figure 2 As shown, the algorithm flow is as follows:
[0033] First, use the PTX instruction generator to automatically generate all the instructions in the NVIDIA PTX file and their modifier codes, then compile these PTX files into cubin with ptxas, and disassemble them through cuobjdump, and finally parse the disassembled information through assembly The instMap variable is represented as an instMap variable, which is used to decode the input of the solver. The structure of instMap includes: operation code, instruction, modifier code, all operands and corresponding operand types, etc.
[0034] Operands can be registers (R5), global memory ([R6+0x20]), constant memory (C[0x2][0x40]), shared memory ([0x50]), immediate data (0x9a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com