

Method for processing data offline in real time on the basis of Spark big data frame
A real-time processing and big data technology, applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., can solve the problem that offline data and real-time data cannot be processed at the same time, and achieve strong scalability and fault tolerance, data processing Efficient and perfect effect of the process
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0038] The present invention will be further described in detail below in conjunction with the embodiments and the accompanying drawings, but the embodiments of the present invention are not limited thereto.
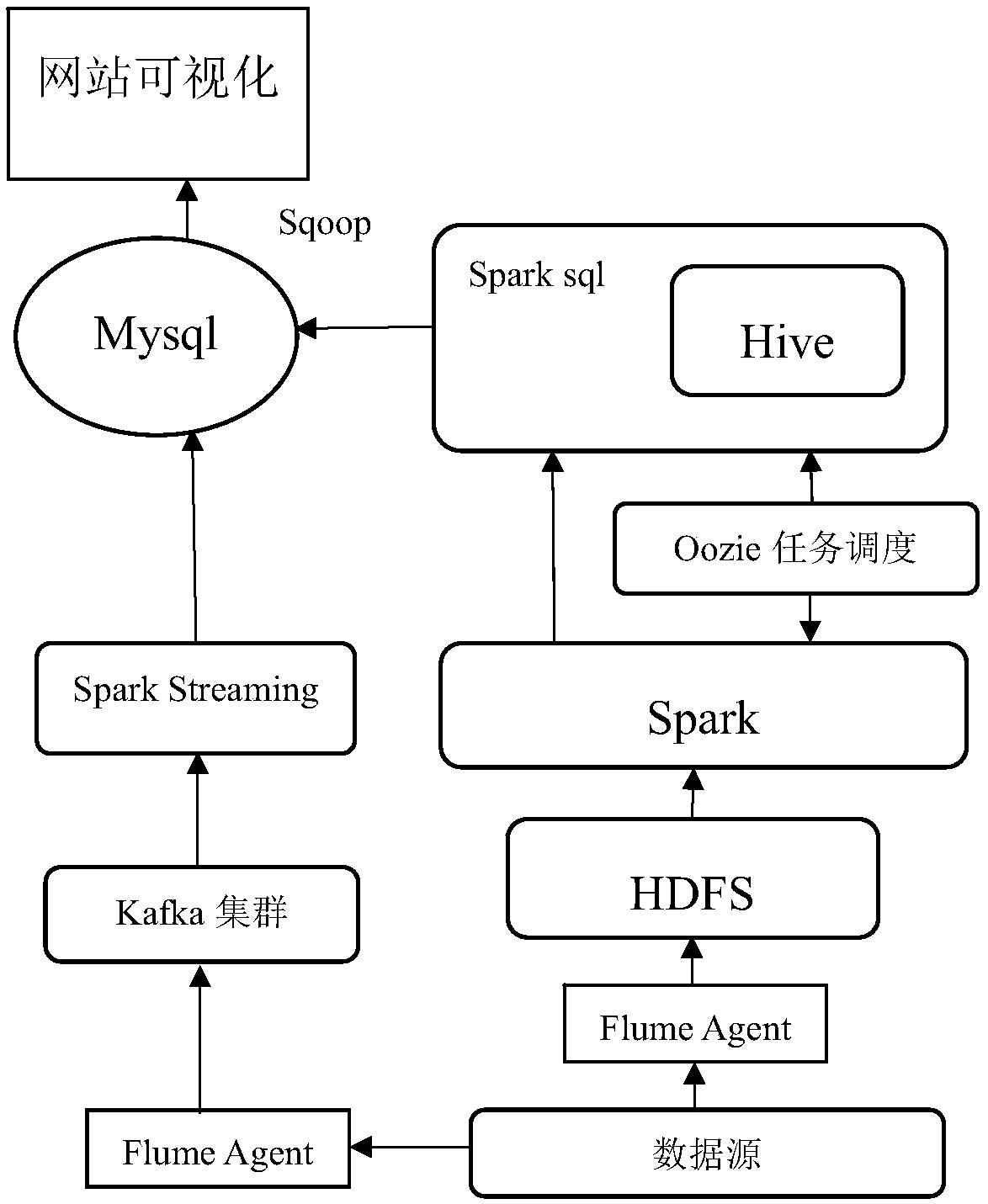
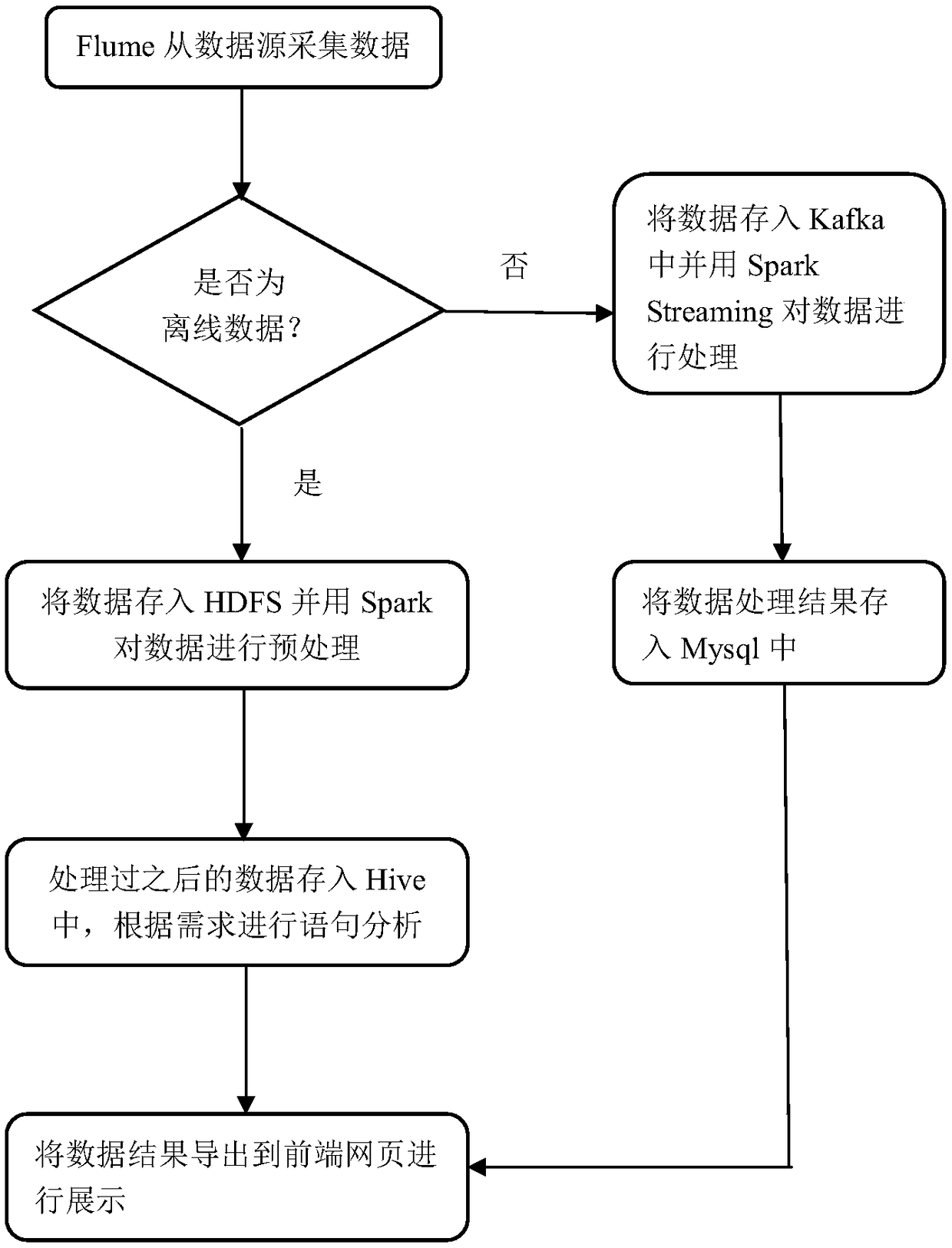
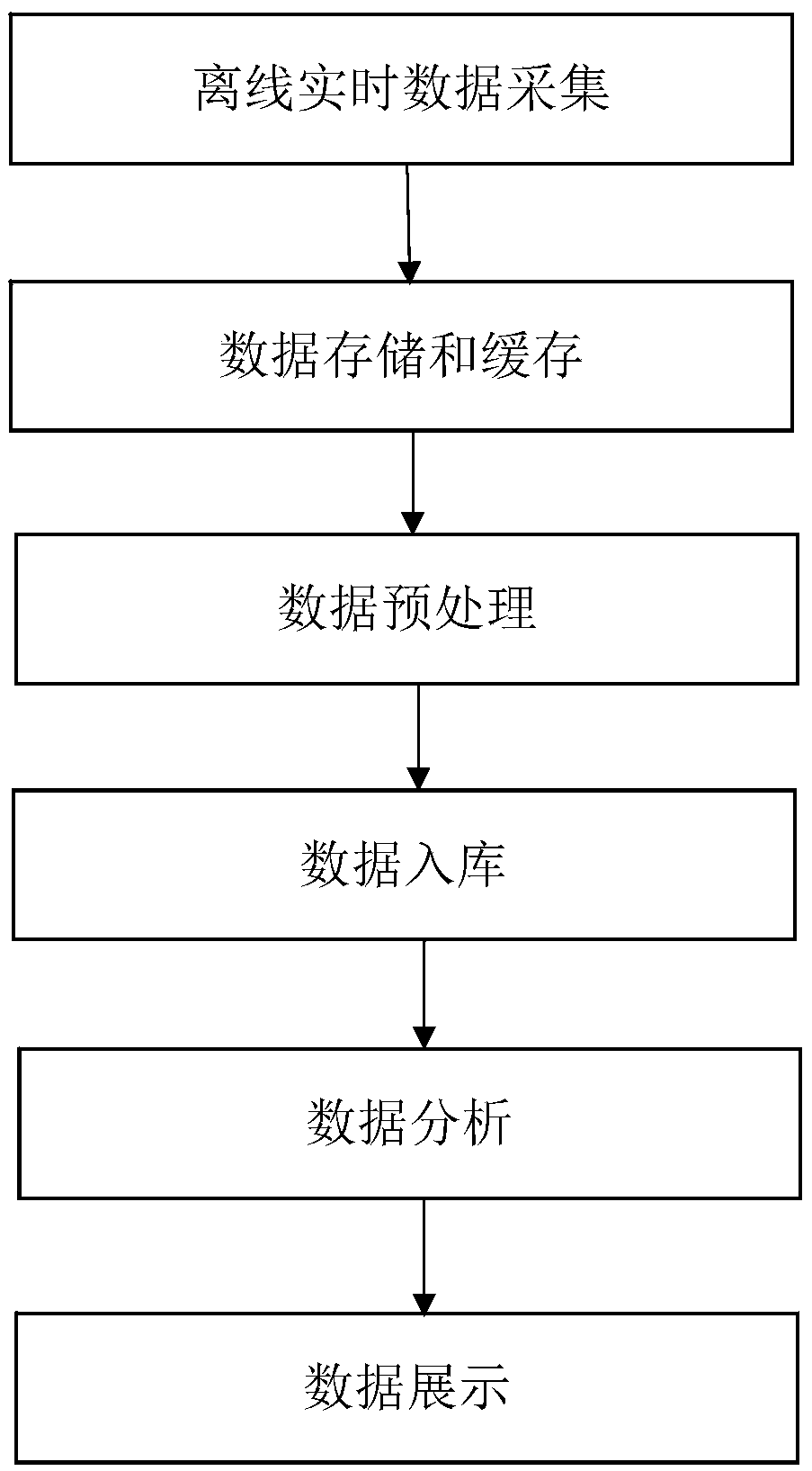
[0039] Such as figure 1 , 2 , 3, a method for offline real-time processing of data based on the Spark big data framework, comprising the following steps:
[0040] Step 1. Offline real-time data collection
[0041] Build the Spark platform environment on the machine and install Mysql, Flume and other related software. Configure Flume-related configuration files to transmit data in Avro mode. Each machine runs a Flume agent, and a Flume agent contains multiple Sources and Sinks, and the Channel serves as the channel connecting the two.
[0042] Step 2. Data storage and caching
[0043] Source collects data from the data source and transmits it to Channel, Sink collects data from Channel and outputs it, the output offline data is uploaded to the HDFS distributed file s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More