

On-the-fly redundancy operation for forming redundant drive data and reconstructing missing data as data transferred between buffer memory and disk drives during write and read operation respectively
a technology of redundant drive and write and read operation, applied in the field of digital data storage, can solve the problems of sharp drop in reliability, limited system performance, and inability to keep up with the speed of disk drive technology, so as to reduce the cost and complexity of disk array controller apparatus, improve disk array performance, and improve disk array performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
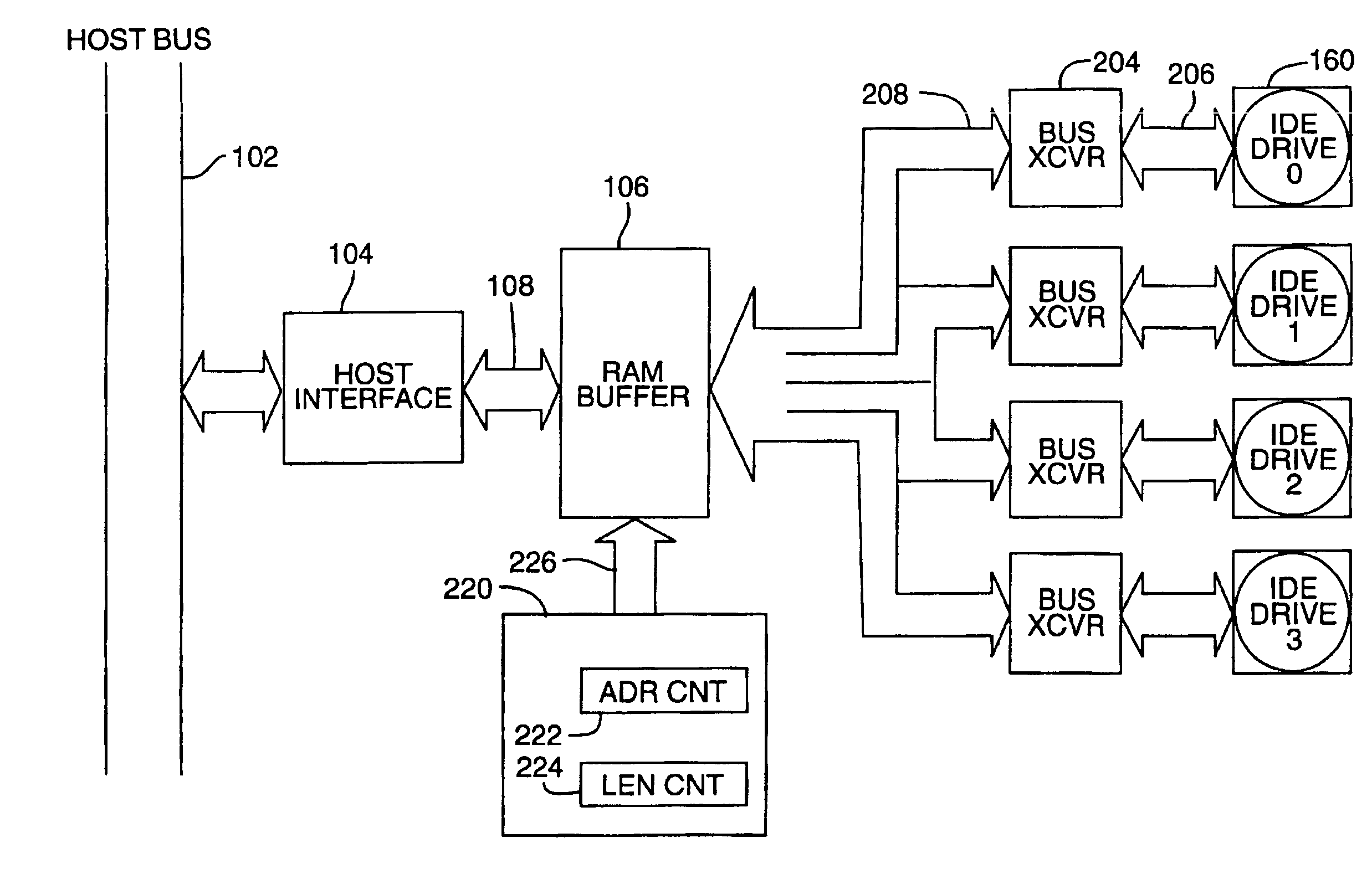
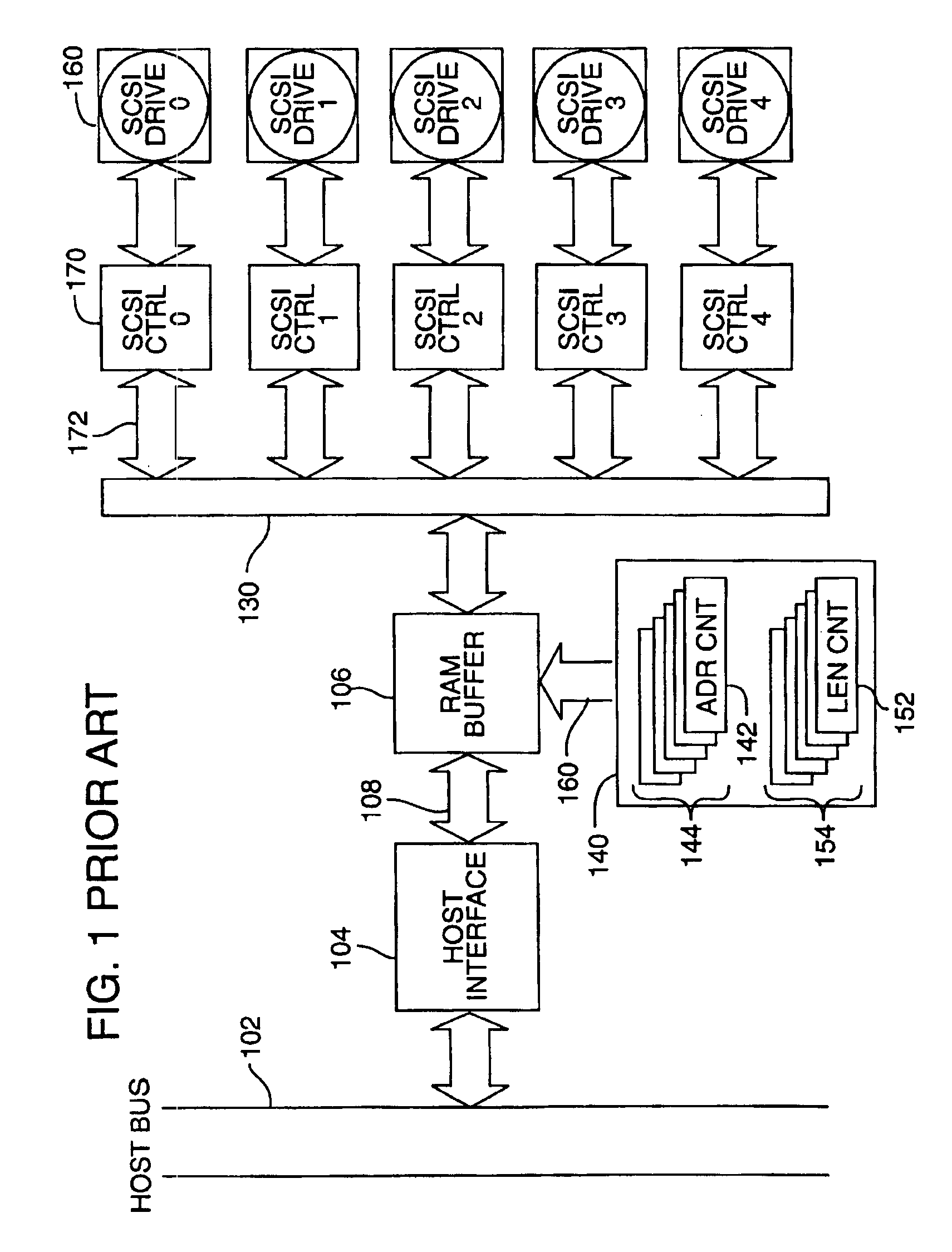
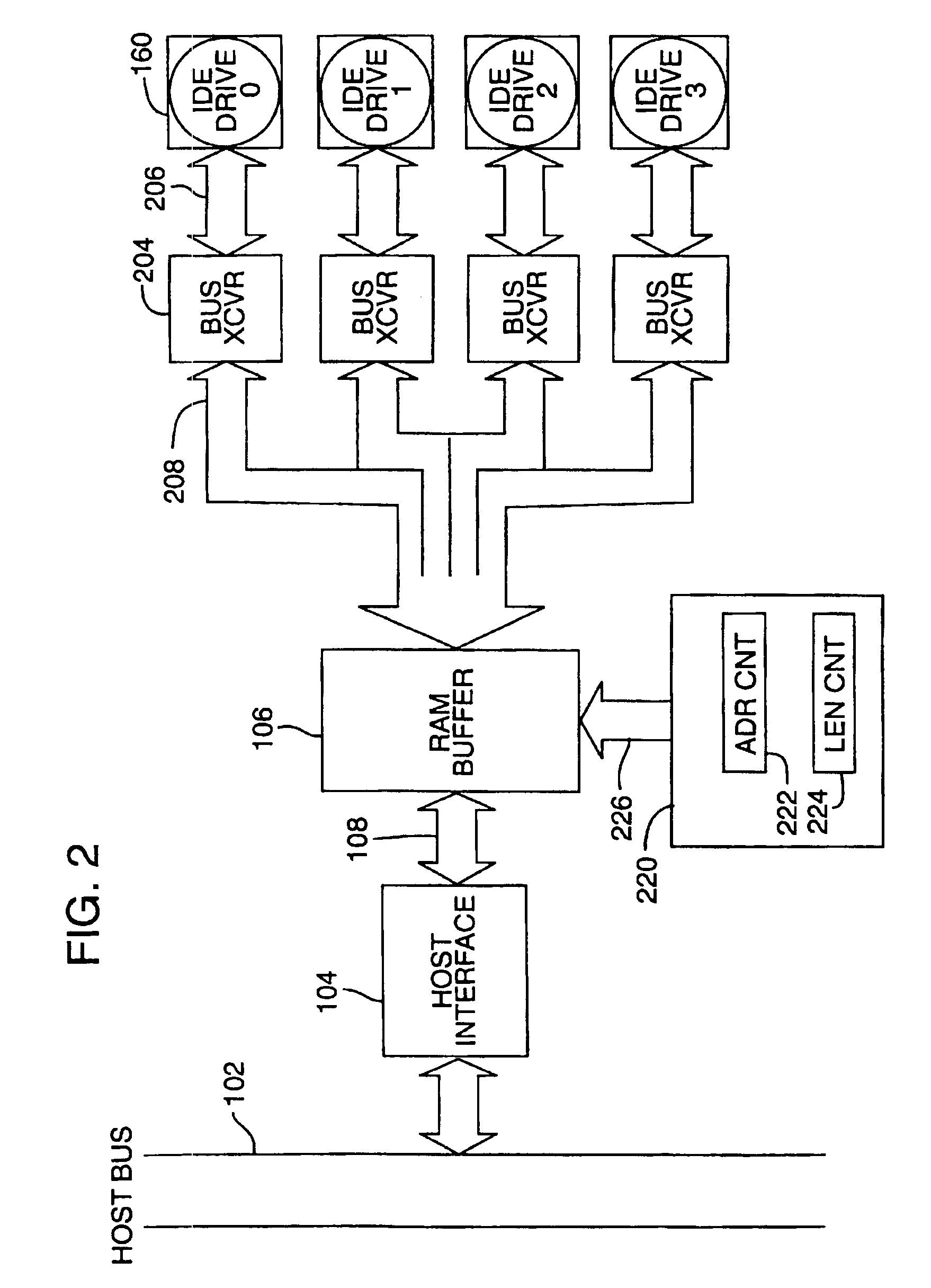
[0049]FIG. 2 is a hardware block diagram illustrating one embodiment of the invention as applied to an array of IDE drives (0-3) so as to provide synchronous data transfer. The host bus 102, host interface 104 and RAM buffer 106 (also referred to herein as the “buffer memory” or “cache”) were described with reference to FIG. 1 previously. In the system of FIG. 2, each of the disk drives, IDE drive 0 through IDE drive 3, is coupled to the RAM buffer 106 through a respective bus transceiver circuit having the same width as the drive interface (for example 16 bits or 2 bytes). For example, drive 0 is coupled to bus transceiver (“BUS XCVR”) 204 via path 206 and bus transceiver 204 in turn is coupled via path 208 to the RAM buffer 106.
[0050]Support of the drive interfaces requires two types of information transfers, control and data. The data paths are shown in FIG. 2 as described. The control information shares 206—the drive data port, but does not come from the RAM. Another path, not s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More