

A Rapid Method for Analyzing Eukaryotic Proteomics Data
A protein genome and eukaryotic technology, applied in the field of protein genome data analysis, can solve the problems of limited application range, only support data statistics, and high limitations, and achieve the effects of improving credibility, rapid identification and analysis, and improving coverage
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

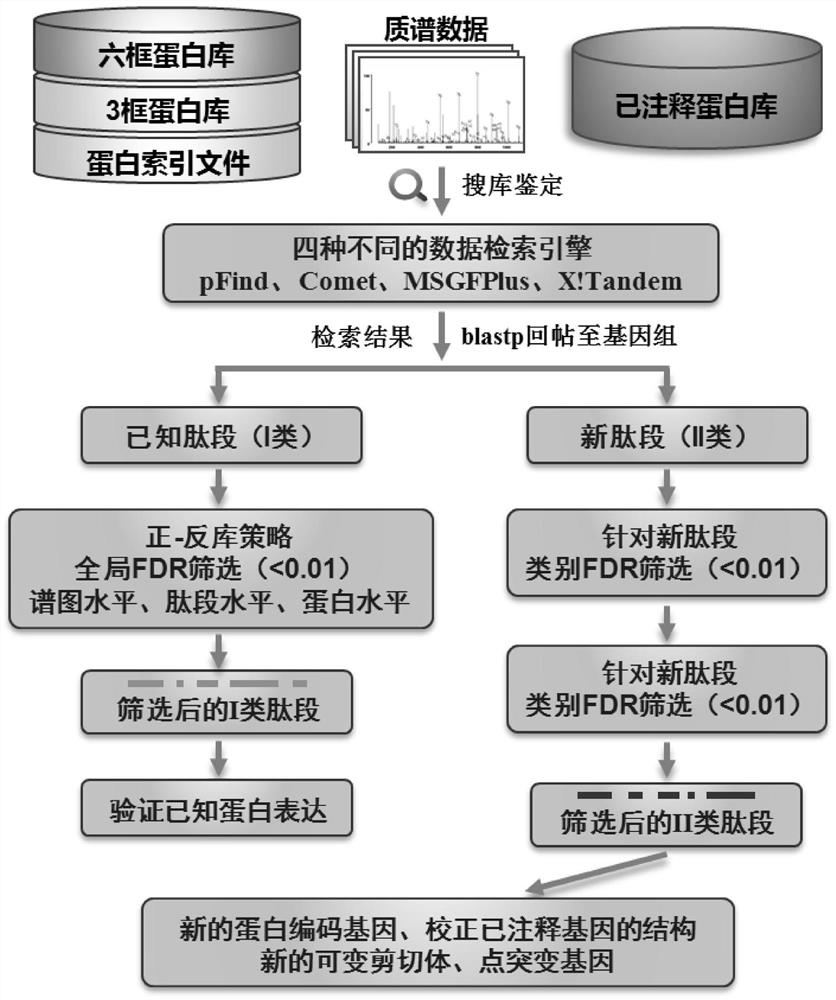
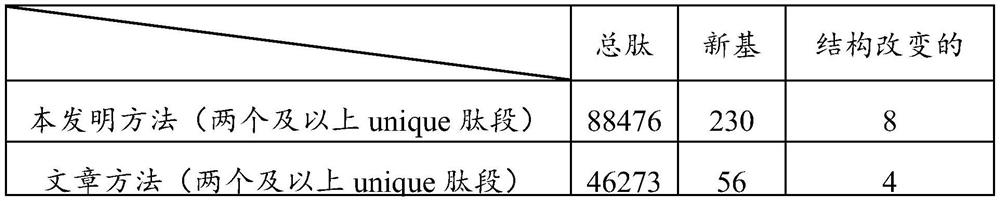
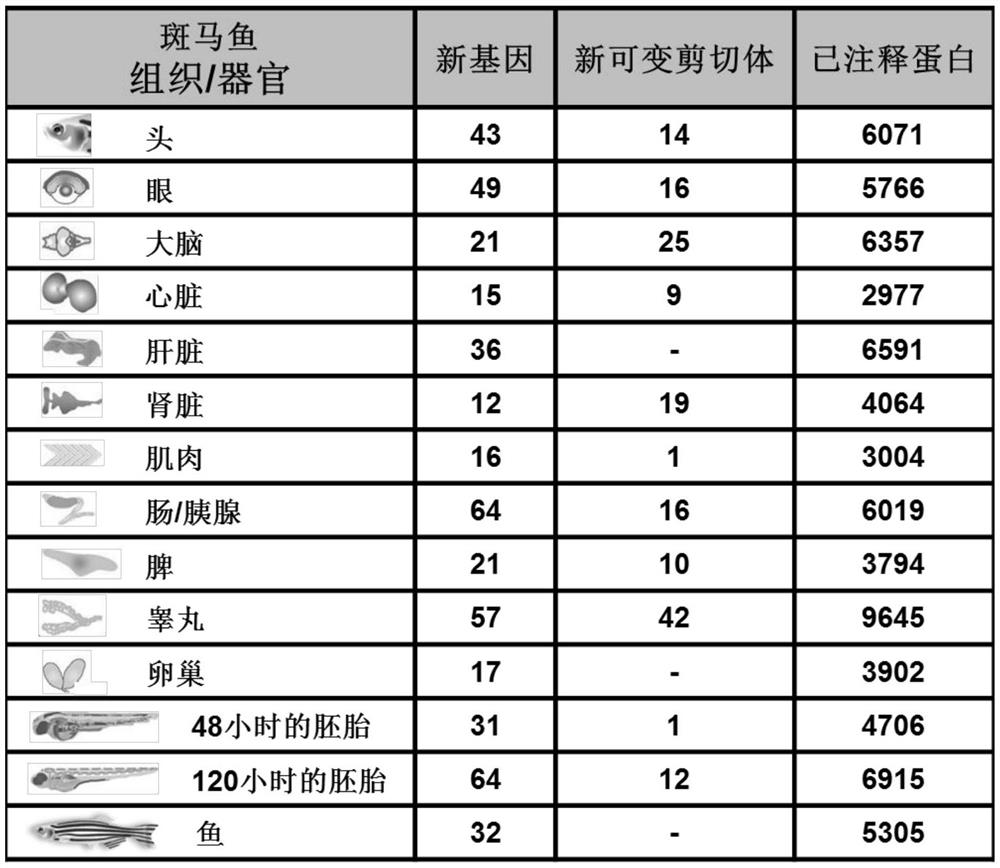
Examples
Embodiment 1
[0068]Mass spectrum data in embodiment 1 comes from published article [Kelkar DS, Provost E, Chaerkady R, Muthusamy B, Manda SS, Subbannayya T, Selvan LDN, Wang CH, Datta KK, Woo S, DwivediSB, Renuse S, Getnet D, Huang TC, Kim MS, Pinto SM, Mitchell CJ, Madgundu AK, Kumar P, Sharma J, Advani J, Dey G, Balakrishnan L, Syed N, Nanjappa V, Subbannayya Y, Goel R, Prasad TSK, Bafna V, Sirdeshmukh R, Gowda H, Wang C, Leach SD, Pandey A, "Annotation of the Zebrafish Genome through an Integrated Transcriptomic and Proteomic Analysis", Molecular & Cellular Proteomics, 2014, 13:3184-3198]
[0069] Example 1
[0070] Zebrafish genome re-annotation, the steps are as follows:
[0071] Download the whole genome sequence of zebrafish from the Ensembl website, the GFF format file, the protein library sequence of the proteome (46260 known protein sequences are predicted), and the zebrafish transcriptome sequence from NCBI.
[0072] Combine the assembled transcriptome data, EST sequences and ...
Embodiment 2
[0092] Phaeodactylum tricornutum genome re-annotation, the steps are as follows:
[0093] 1) According to the experimental method in the literature [Yang MK, Yang YH, Chen Z, Zhang J, Lin Y, Wang Y, Xiong Q, Li T, Ge F, Bryant DA, Zhao JD, "Proteogenomic analysis and global discovery of posttranslational modifications in prokaryotes",2014,111(52):E5633-E5642], extract Phaeodactylum tricornutum protein, and carry out enzymatic digestion to the total protein to obtain a peptide mixed solution, and use Thermo LTQ Exactive mass spectrometer to detect the obtained peptide solution, Mass spectrometry data were collected, and a total of 1,555,391 mass spectrograms were collected.
[0094] 2) Using the same method as in Example 1, download the complete genome sequence of Phaeodactylum tricornutum from the JGI Genome Portal website, the transcriptome sequence, the GFF format file, the protein library sequence of the proteome (10567 known protein sequences), and Use ProteoWizard to con...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More