

Power distribution method in downlink NOMA of depth deterministic strategy gradient
An allocation method and a deterministic technology, applied in the field of NOMA resource allocation, can solve the problems that it is not easy to find the optimal solution, the numerical simulation method does not have an accurate system model, and consumes a lot of time, so as to solve the problem of spectrum scarcity and improve Average transfer rate, effect of improving utilization efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
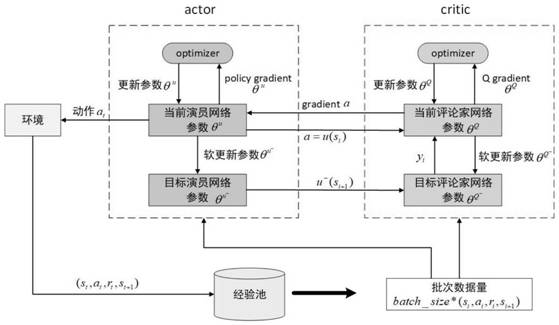
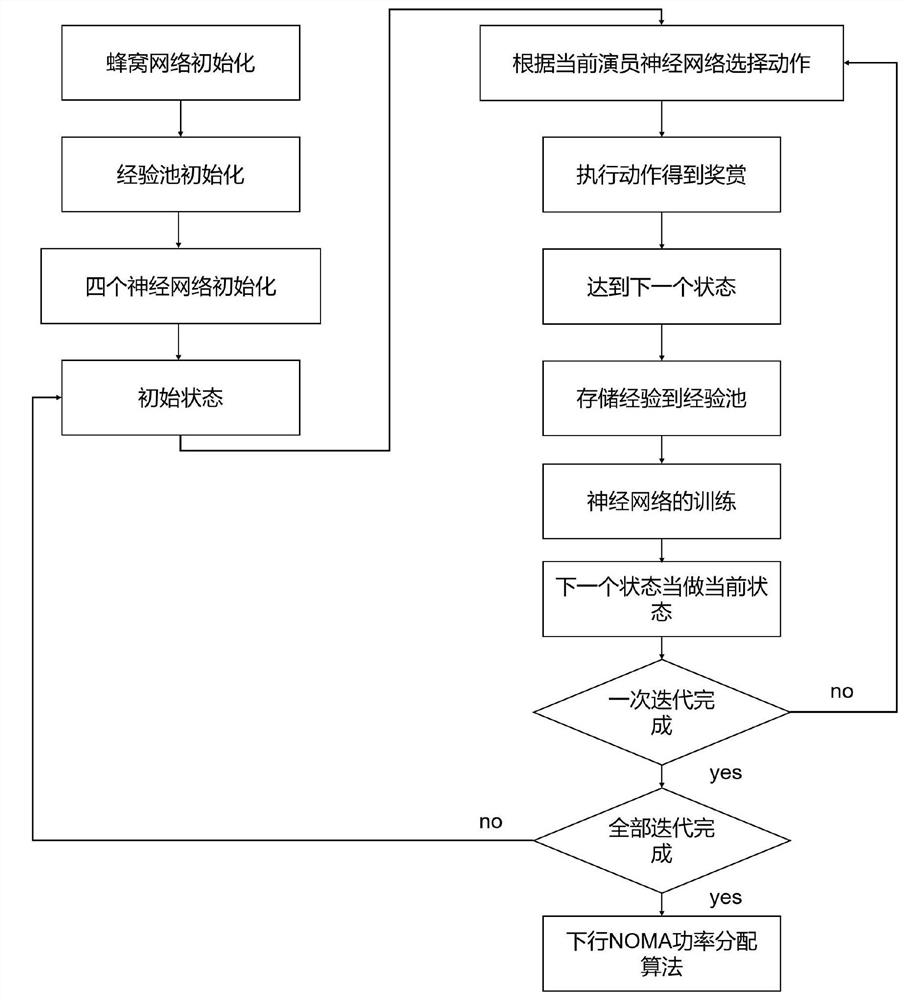
[0056] Embodiment 1: as figure 1 Shown is a structural diagram of a cellular network power allocation method according to an embodiment of the present invention. This embodiment provides a downlink NOMA system power allocation method based on a deep deterministic policy gradient algorithm. The specific steps are as follows:
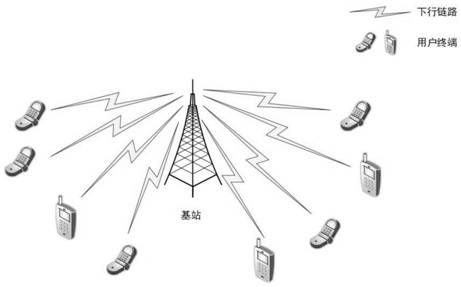
[0057] 1) Initialize the downlink NOMA system simulation environment, such as Figure 4 Shown is a simulated communication system diagram, including a base station and multiple end users. Considering the complexity of decoding at the receiving end, consider the case of two users on one subchannel;
[0058] 2) Initialize the weight parameters of the two neural networks contained in the actor network module and the critic network module;
[0059] 3) Use correlation algorithms to complete the matching work between users and channels, and adopt the method of equal power distribution between sub-channels;
[0060] 4) Obtain the initialization state, first ca...
Embodiment 2
[0070] Embodiment 2: This embodiment specifically explains the small-scale fading, large-scale fading, action set, neural network structure, and parameter update method of the target network in embodiment 1.
[0071] (1) Small-scale fading, the formula is:
[0072] in, and The formula for calculating the correlation coefficient ρ is: ρ=J 0 (2πf d T s )J 0 ( ) represents the zero-order Bessel function of the first kind, f d represents the maximum Doppler frequency, T s Indicates the time interval between adjacent moments, in milliseconds.
[0073] (2) Large-scale fading, the formula is: PL -1 (d)=-120.9-37.6 log 10 (d)+10log 10 (z)
[0074] Among them, z is a random variable that obeys the logarithmic normal distribution, and the standard deviation is 8dB, and d represents the distance from the transmitting end to the receiving end, and the unit is km.
[0075] (3) The action set is a set of continuous values, ranging from 0 to 1, but not including 0 and 1. The ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More