

Method and system for variable mass underwater vehicle obstacle avoidance based on deep reinforcement learning
An underwater vehicle, reinforcement learning technology, applied in neural learning methods, design optimization/simulation, biological neural network models, etc., can solve problems such as inability to converge, slow convergence, and slow actor-critic network convergence.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
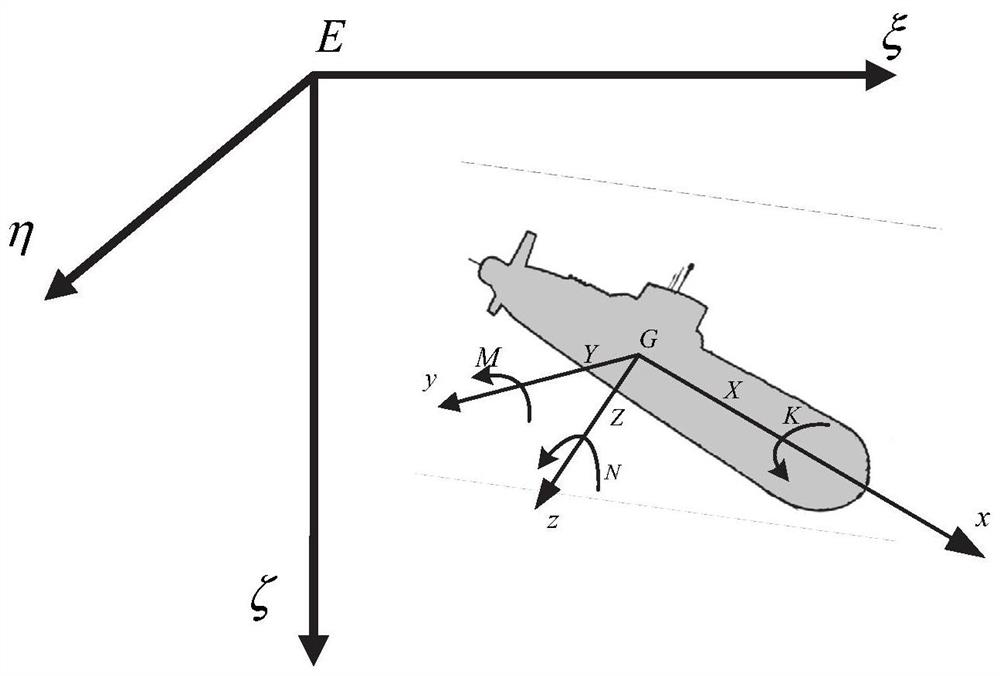
[0042] Such as figure 1 As shown, the present embodiment provides a method for avoiding obstacles of a variable mass underwater vehicle based on deep reinforcement learning, including:
[0043] S1: Construct an obstacle avoidance simulation model based on a deep reinforcement learning network according to the motion state of the variable-mass underwater vehicle and the action of the actuator;
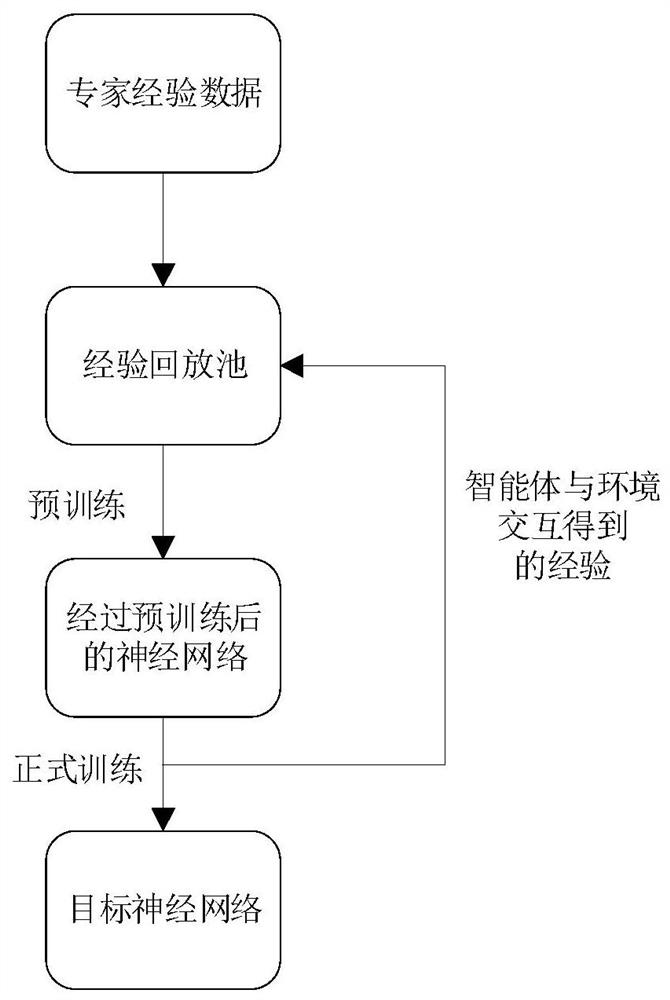
[0044] S2: Store the pre-acquired complete trajectory of historical obstacle avoidance tasks as expert data into the experience playback pool, obtain the current execution action according to the initial motion state and Gaussian noise of the variable-mass underwater vehicle, and obtain the new operation state and current execution action according to the current execution action The reward value of the action is stored in the experience playback pool;
[0045] S3: Train the obstacle avoidance simulation model based on the deep reinforcement learning network according to the experience...
Embodiment 2
[0111] This embodiment provides a variable mass underwater vehicle obstacle avoidance system based on deep reinforcement learning, including:
[0112] The model construction module is configured to construct an obstacle avoidance simulation model based on a deep reinforcement learning network according to the motion state of the variable-mass underwater vehicle and the action of the actuator;
[0113] The experience acquisition module is configured to store the pre-acquired complete trajectory of the historical obstacle avoidance task as expert data into the experience playback pool, obtain the current execution action according to the initial motion state of the variable-mass underwater vehicle and Gaussian noise, and obtain the new execution action according to the current execution action. The running status and the reward value of the currently executed action are stored in the experience playback pool;
[0114] The training module is configured to train the obstacle avoid...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More