

High-performance realization method of gemm dense matrix multiplication on Shenwei 26010 many-core CPU
A technology of dense matrix and implementation method, applied in the fields of instrumentation, calculation, electrical digital data processing, etc., can solve the problem of low performance, open source BLAS math library Shenwei many-core processor 26010 optimized, can not give full play to many-core computing capabilities, etc. problem, to achieve the effect of improving the performance of the function
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0036] The present invention will be described in detail below in conjunction with the accompanying drawings and embodiments.
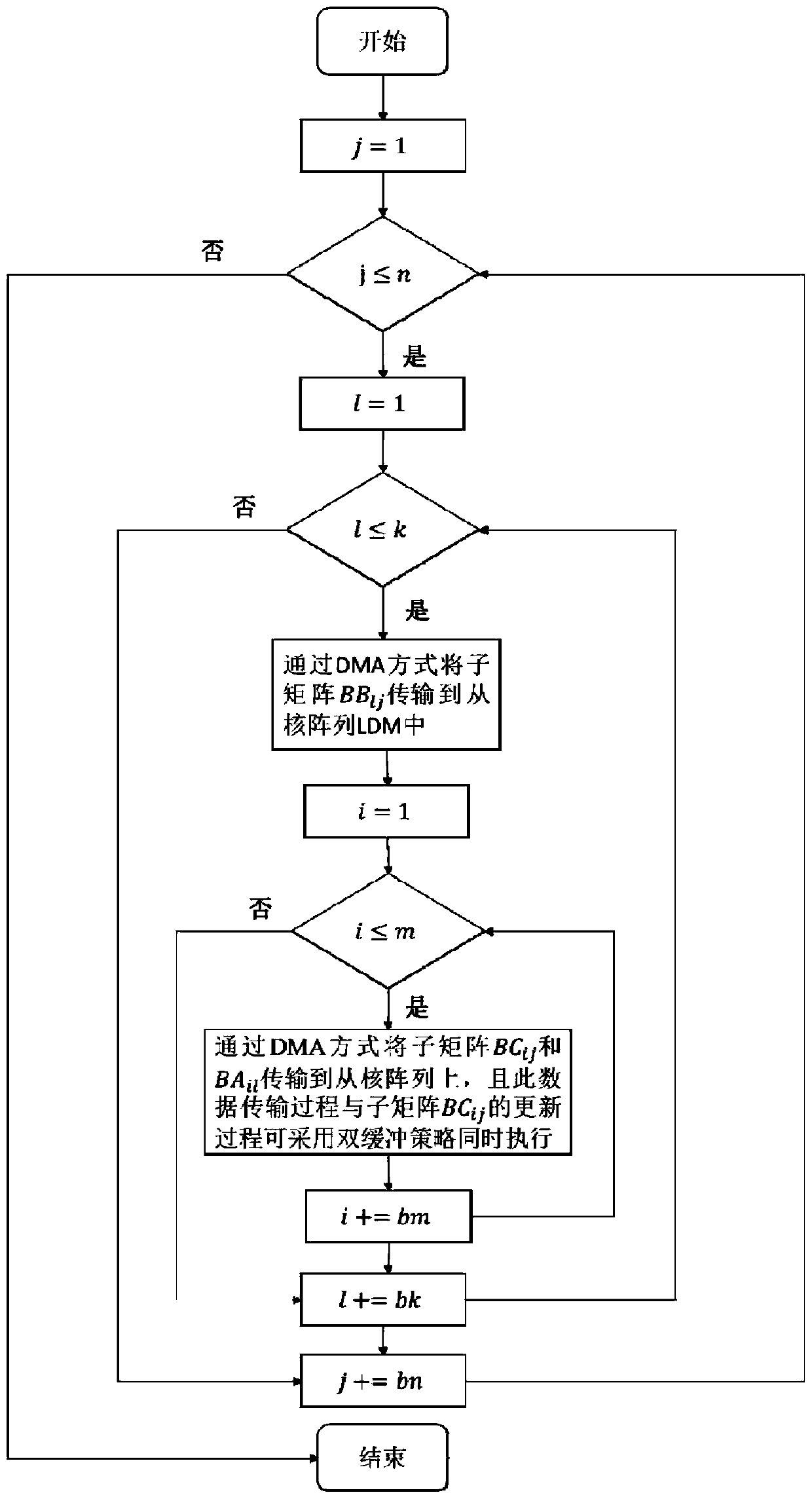
[0037] Such as figure 1 As shown, the specific implementation adopts the three-level code framework of "interface interface layer-scheduling task scheduling layer-kernel assembly computing layer", which is described as follows:
[0038] (1) Interface interface layer function: This layer is a function interface, which checks the input parameters and returns an error code if an illegal parameter is judged; in addition, according to the accuracy and transposition of the input matrix A, B, call the corresponding scheduling Task scheduling layer function;
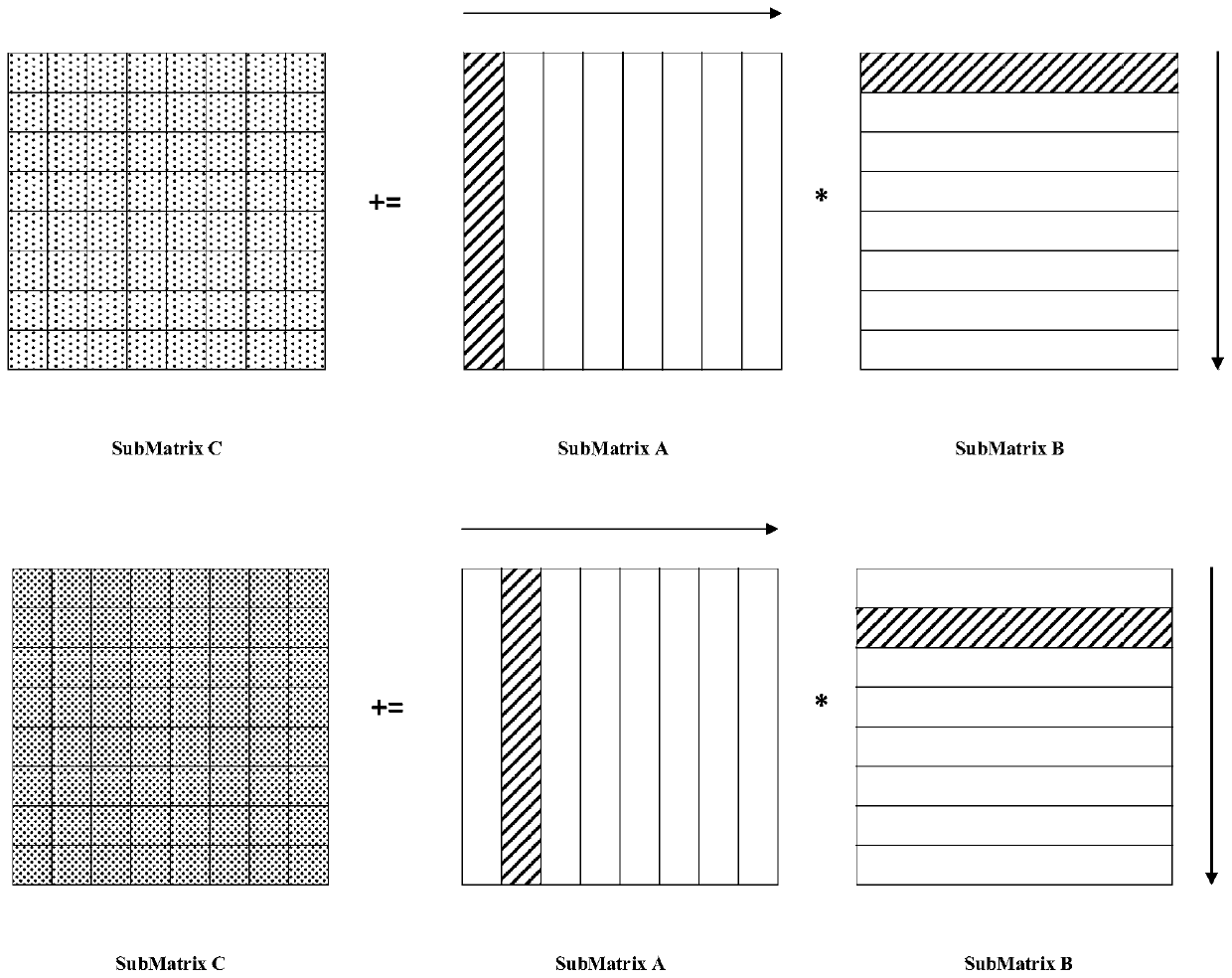
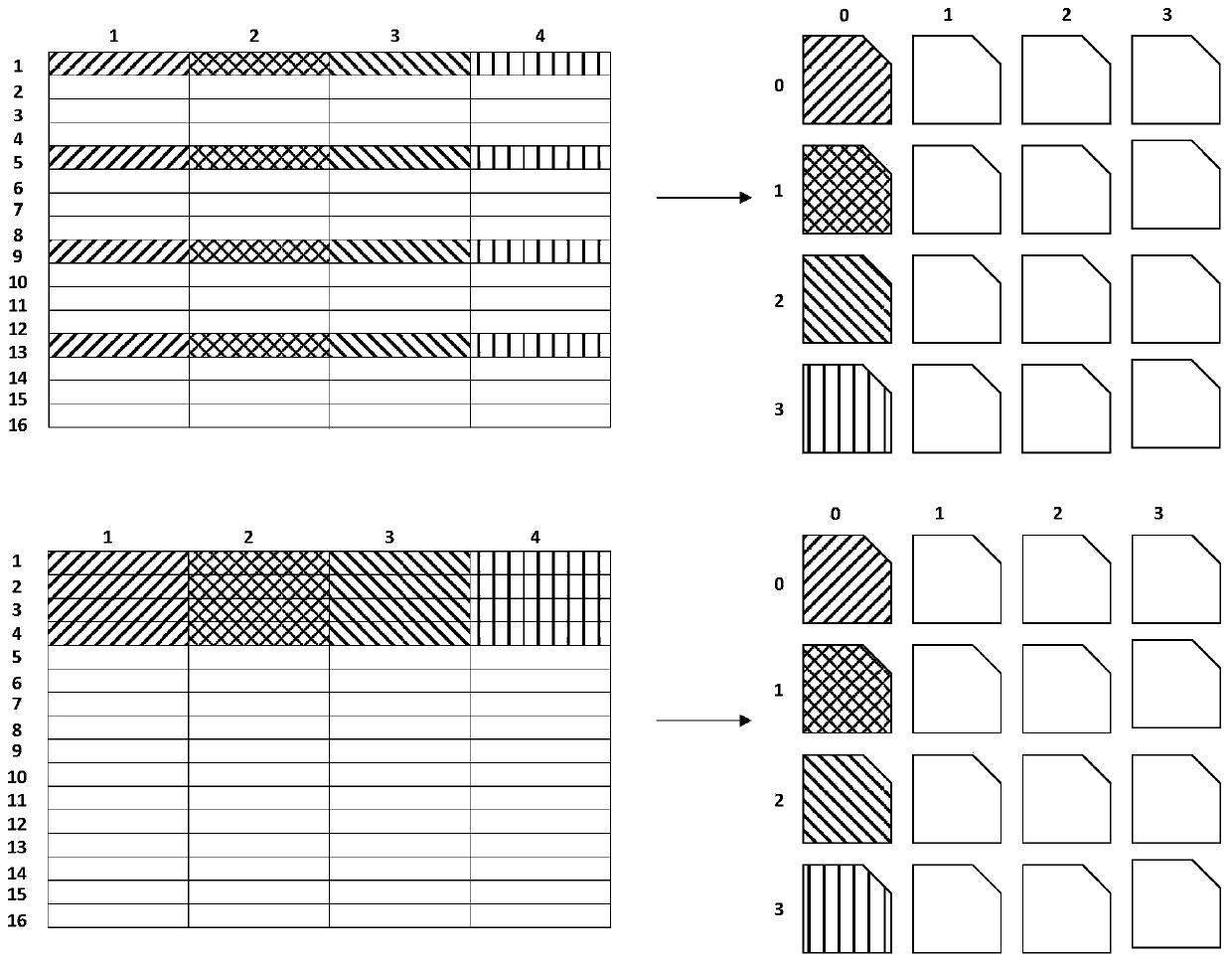
[0039] (2) Scheduling task scheduling layer function: It is called by the interface interface layer function, and calls the kernel assembly computing layer function. The updating order of the matrix C is controlled through the n-k-m three-layer loop, and the C sub-matrices are updated serially, with ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More