

Systems and methods for preparing data for use by machine learning algorithms
a machine learning algorithm and data technology, applied in the field of machine learning, can solve the problems of no data at all, typographical errors, and abounding integrity and quality of data, and achieve the effect of improving the accuracy and utility of a primary machine learning algorithm and improving performan
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
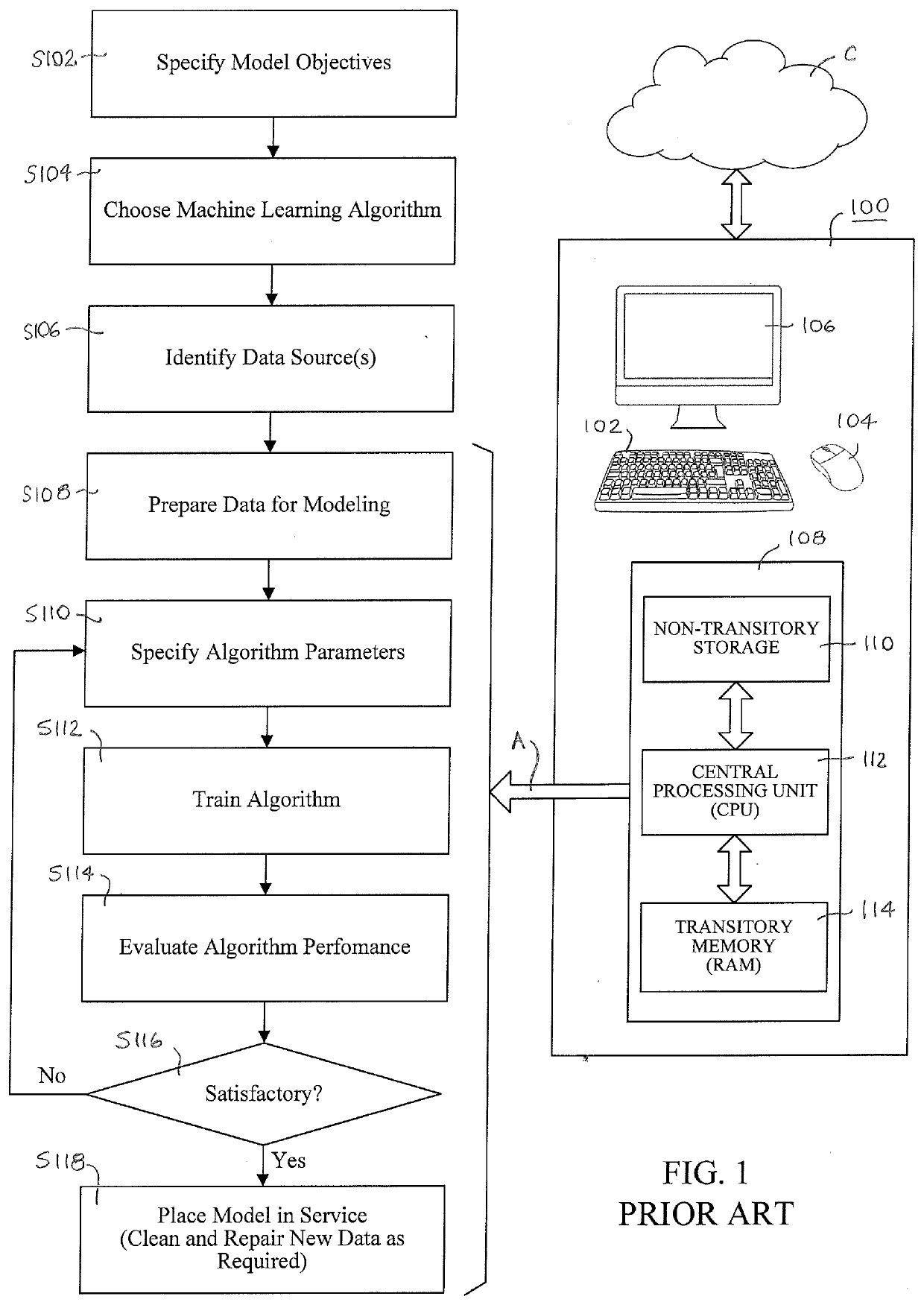
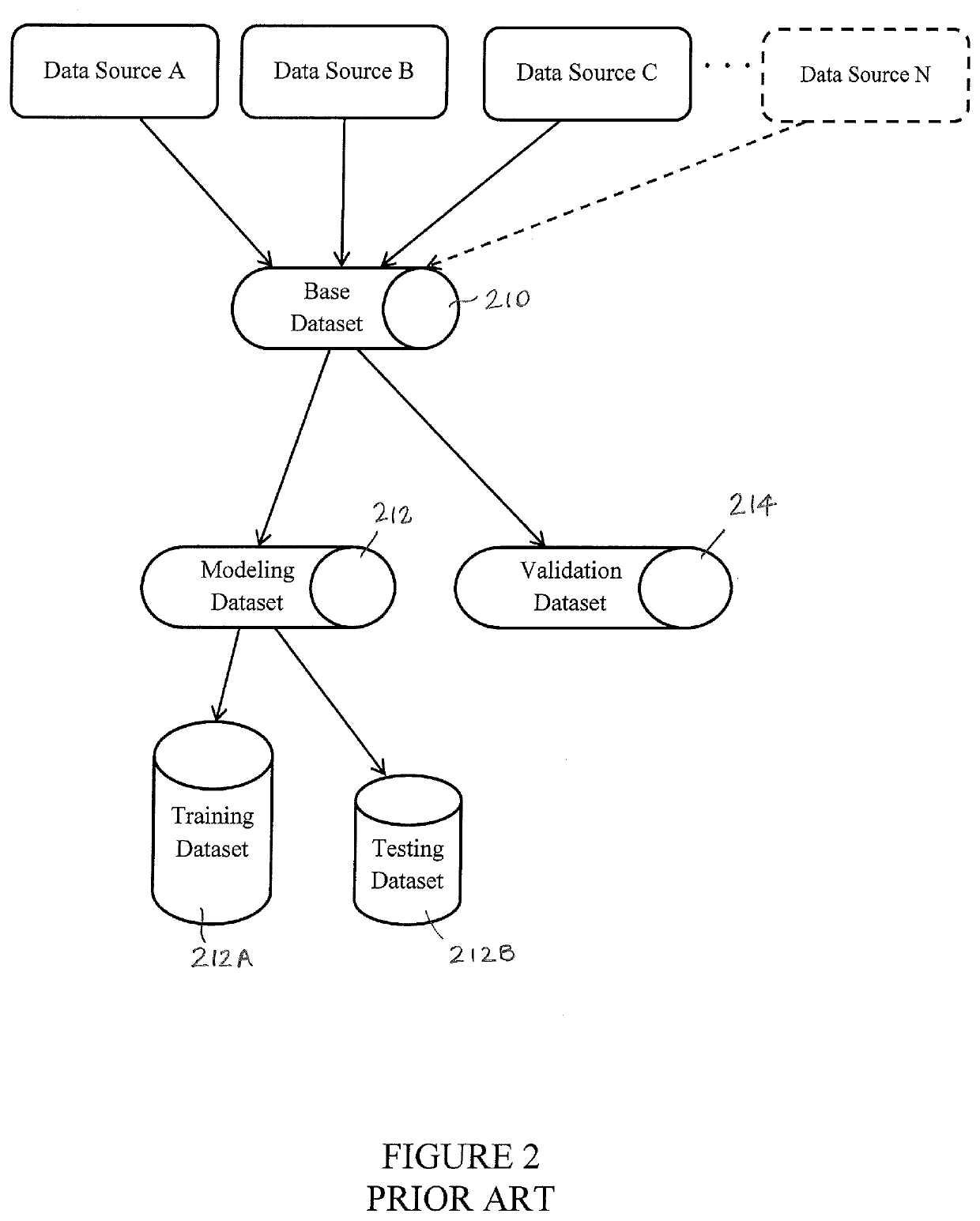
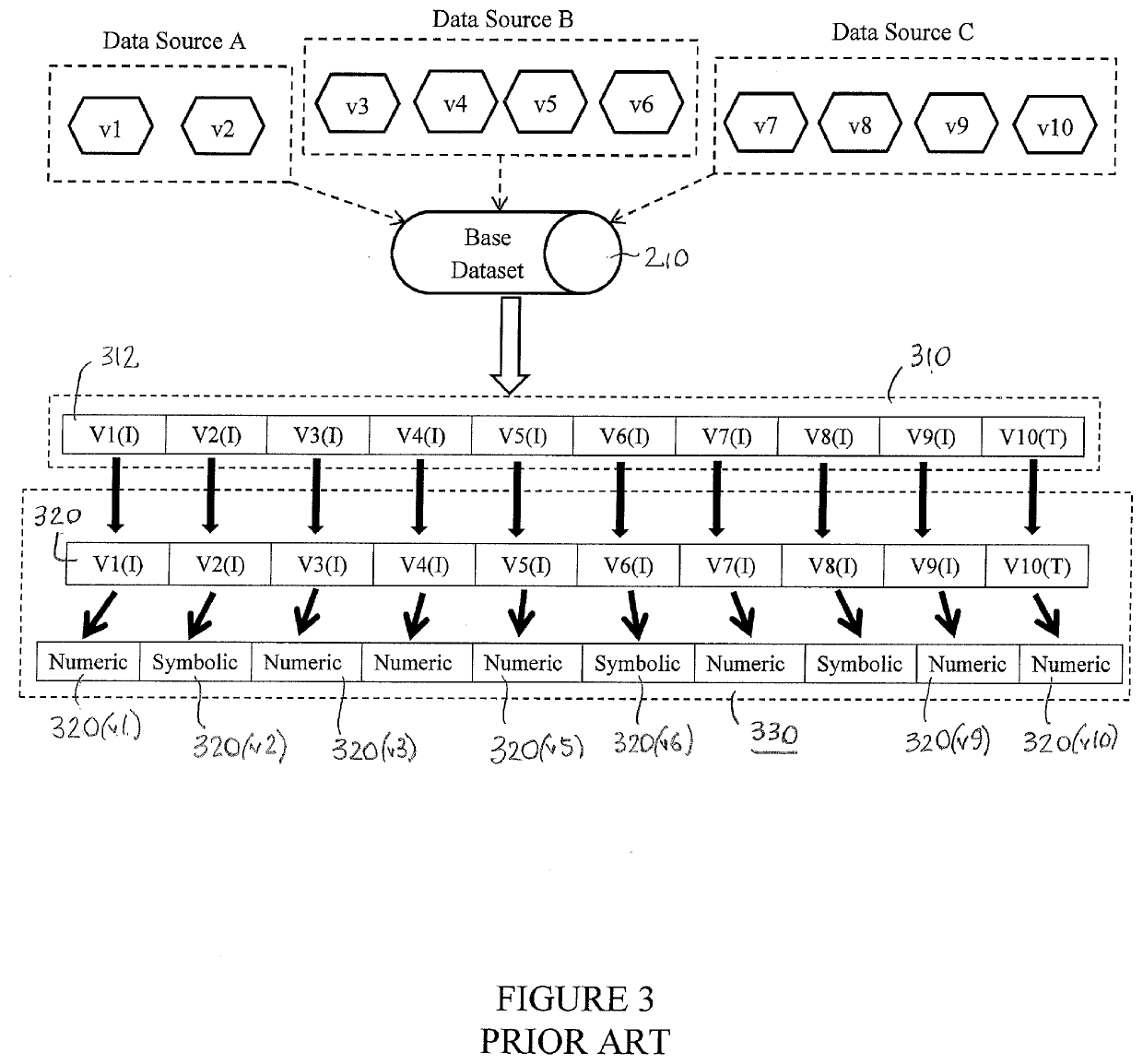
[0041]The description that follows assumes a thorough understanding of the basic theory and principles underlying what is commonly referred to as “machine learning.” It will be readily understood by a person skilled in the art of machine learning, neural networks, and related principles of mathematical modeling to describe examples of particular embodiments illustrating various ways of implementing the present subject matter. Accordingly, certain details may be omitted as being unnecessary for enabling such a person to realize the embodiments described herein.
[0042]As those skilled in the art will recognize, in the description of the subject matter disclosed and claimed herein control circuitry and components described and depicted in the various figures are meant to be exemplary of any electronic computing system capable of performing the functions ascribed to them. Such a computing system will typically include the necessary input / output interface devices and a central processing ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More