

Improvements in variant detection
A variant and sample technology, applied in the field of detection of variant DNA, can solve problems such as impossibility, difficulty in monitoring, and possibility of limiting applications
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
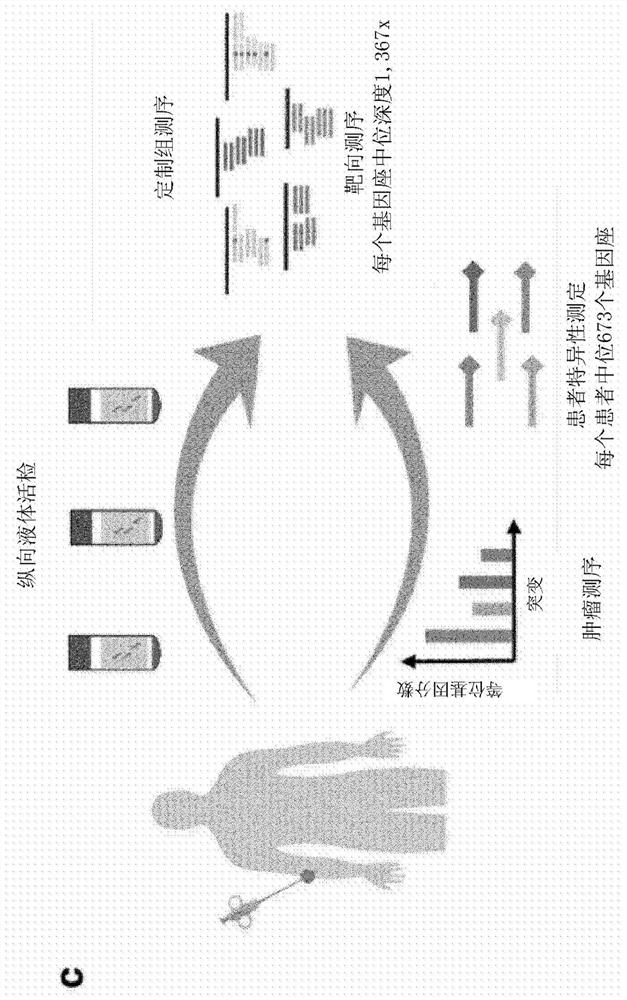
[0297] Example 1 - Identification of Patient-Specific Mutations from Tumor and Plasma
[0298] To obtain high sequencing depth at defined loci mutated in patient tumors, custom hybrid capture sequencing panels were designed based on single nucleotide variants (SNVs) identified in the sequencing of tumor biopsies. SNVs with ≥1 mutant read and ≥10 total reads were selected from exome sequencing (9 patients) or targeted sequencing (1 patient) of baseline metastatic biopsies. The median number of SNVs identified per patient was 673 (IQR 250-1,209; Figure 7a). Patient-specific variants were identified (not shown). Furthermore, to allow de novo identification of mutations in plasma, the coding sequences and untranslated regions of the following genes were included in the panel design: ARID2, BRAF, CDKN2A, NF1, PTEN, and TP53, as well as 37 additional genes commonly mutated in melanoma. Hotspot loci (not shown) among the genes of . The final group design covers 1.527Mbp.
[029...
Embodiment 2
[0301] Example 2 - Characterization of background error rate
[0302] We sought to understand the background error rate (i.e., the rate at which unanticipated mutated bases were observed) with and without error suppression in TAPAS sequencing data. Bases on either side of the patient-specific variants were investigated because they have comparable sequencing depth and are subject to the same technical bias. To take advantage of this off-target sequencing of patient samples, germline events and potential biosignatures were excluded if they occurred multiple times in samples from the same individual (Methods); these loci were left for subsequent de novo mutation calling.
[0303] Error suppression can be achieved by using read compression to determine consensus sequences for entire read families. To achieve this, repeat reads are based on start and end fragment positions (formerly known as 'endogenous barcodes' 11,12 ) and molecular barcodes are grouped into 'read families'. ...
Embodiment 3
[0304] Example 3 - Variant Read Integration (INVAR)
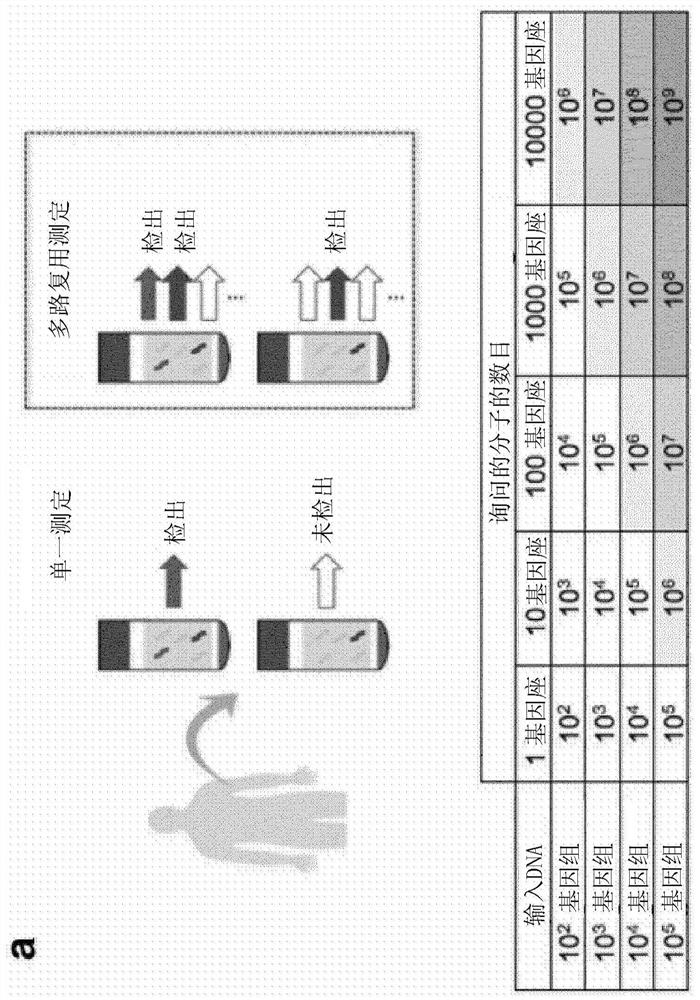
[0305] Using a strict level of error suppression (consensus sequence required in 90% of family members, minimum family size of 5) and a median of 4.4 ng of input, we obtained a median of 3.2 × 10 5 read family (IQR 8.7×10 4 to 6.2×10 5 ), each covering the loci mutated in that patient's cancer. Under the assumption that each such read family corresponds to a single molecule, we are thus able to probe thousands of target molecules per sample even if the starting material contains only ~1300 genome copies.
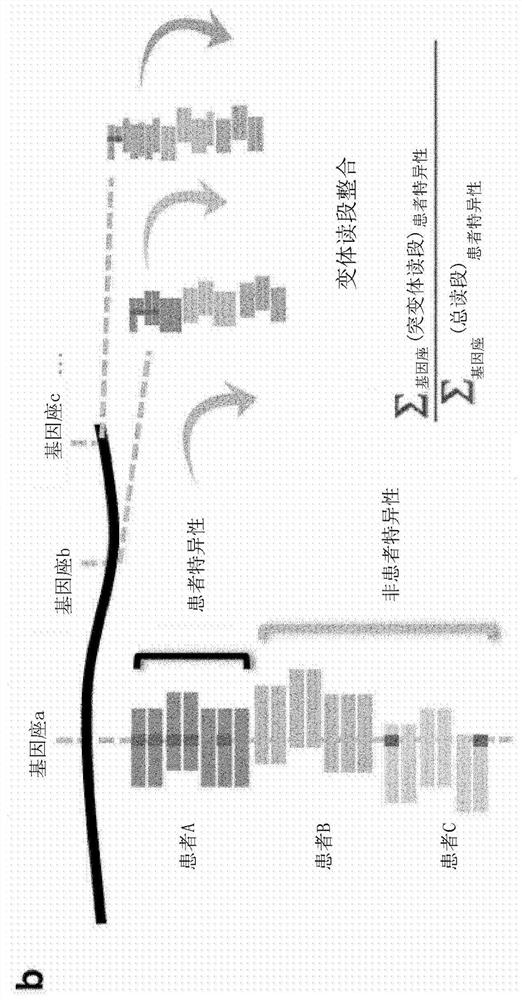
[0306] When ctDNA levels are low, many patient-specific loci will have no mutant DNA fragments at that position ( Figure 7 b). Therefore, to overcome sampling error, all patient-specific read families were aggregated and analyzed together using INVAR ( figure 1 b). For each sample, the "global" mutant allele fraction across all patient-specific loci was calculated as follows:
[0307]
[0308] The significance ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More